|
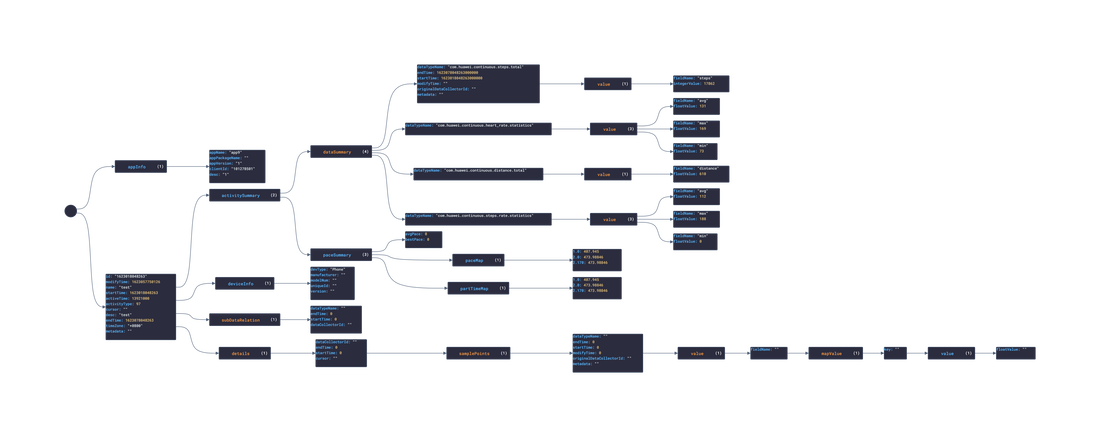
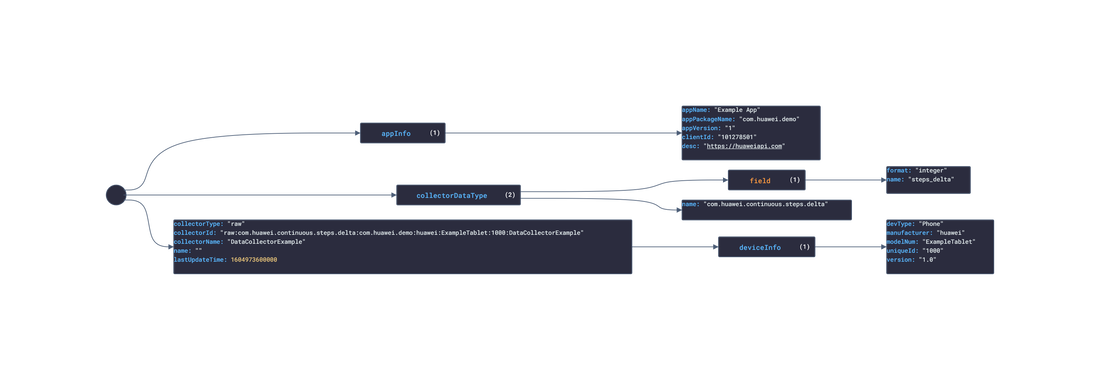
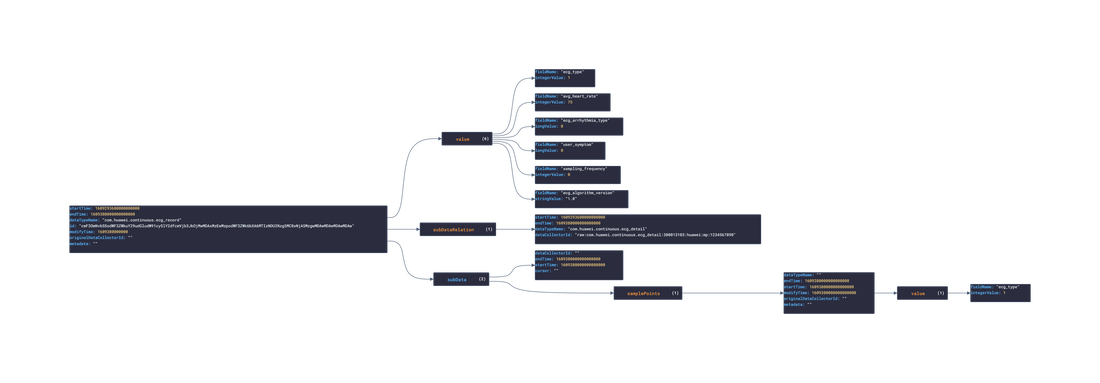
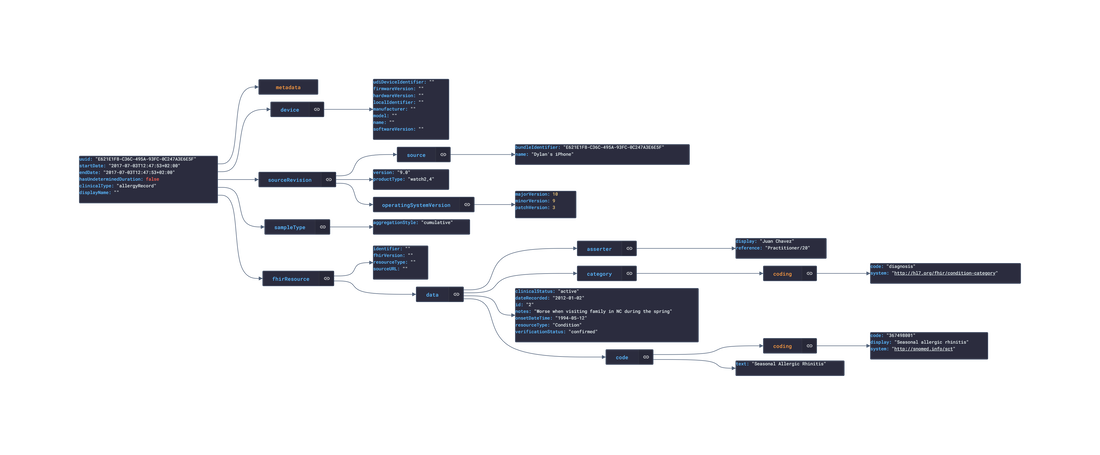
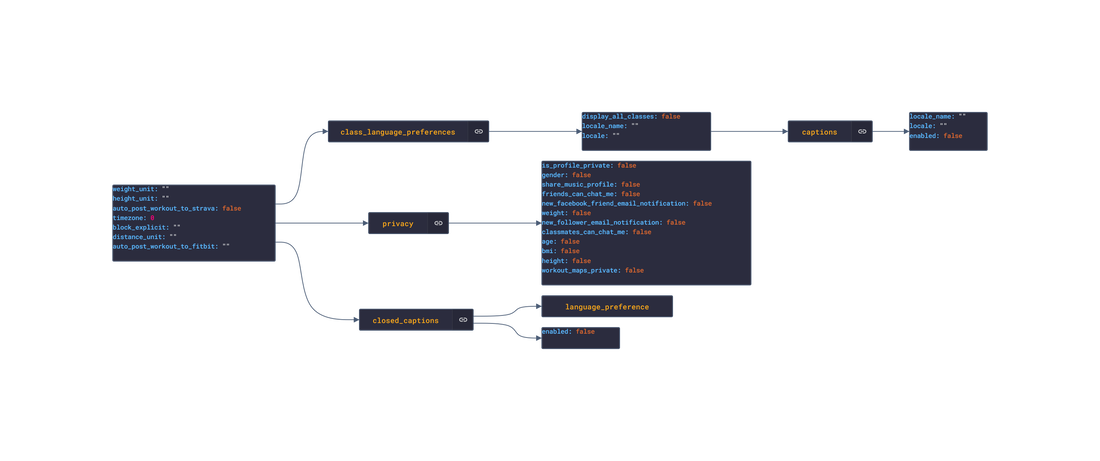
In this post, we are going deeper into the Dynamic Data project, looking at the Huawei dynamic data (library available here on GitHub and at NPM). Opening the library, you’ll see there are 3 types of data objects: ActivityRecord, DataCollector, and HealthRecord. Learn more about dynamic data generators and the benefits of artificial data in software development. About the data source Huawei is a company that develops and sells a range of other consumer electronics products such as laptops, tablets, wearables, and smart home devices. Huawei has grown into a global technology giant and is now one of the world's largest providers of telecommunications equipment and smartphones. Huawei Healthkit is a software development kit (SDK) developed by Huawei that provides developers with access to health and fitness-related data from Huawei wearable devices and smartphones. This data includes information such as step count, heart rate, sleep data, and workout data. The Healthkit API provides developers with a simple and standardized way to access and utilize this data in their own applications, allowing them to create innovative and personalized health and fitness experiences for users. Huawei Healthkit is part of the company's larger ecosystem of software and hardware products designed to enhance the user experience across a range of devices. Approach used Huawei provides both an API and SDK to access and mutate user health data. By inspecting the example data and the reference, several JSON objects were constructed and then stored in an NPM package. Each of these JSON objects then had an associated 'Async' version created. The index file of the package imports these data objects and exports them in a collection called “Data”. These mockup files make up the huawei-data package. The huawei-mockups package imports the files above and goes through each attribute generating artificial (new) data using proprietary functions, such as those found in the utils package. For example, with the ActivityRecord object:
Use case ideas
Explore entirely new use cases
Ideas to combine with some other data sources
Open-source data library We welcome contributions and forks to this data set, and look forward to seeing what developers build in our Liberty. Equality. Data. Slack channel. Considerations for next version/improvements
Join our Slack community; Liberty. Equality. Data. to brainstorm and collaborate with other app developers, designers, and our team.
In this post, we are going deeper into the Dynamic Data project, looking at the Garmin dynamic data (library available here on GitHub and at NPM). Opening the library, you’ll see there are eight types of data objects: dailiesData, dailiesDataAsync, epochsData, epochsDataAsync, sleepsData, sleepsDataAsync, pulseoxData, and pulseoxDataAsync. Learn more about dynamic data generators and the benefits of artificial data in software development. About the data source Garmin is a company that produces a wide range of GPS and navigation products for both consumer and professional markets. Some of their popular products include fitness watches and activity trackers, in-car GPS navigation systems, and handheld GPS devices for outdoor activities such as hiking and cycling. They also produce marine and aviation GPS systems and a variety of wearable technology products such as smartwatches. In addition to their GPS products, Garmin also offers a variety of other products and services related to fitness, outdoor recreation, and technology. These products are designed to help users track their physical activity and exercise, as well as other health and wellness metrics such as sleep, heart rate, and stress levels. Some of the features offered by Garmin's fitness products include:
Approach used Garmin provides an API to connect to the user's data through its Garmin Connect Developer Platform. By inspecting the example data and the reference, several JSON objects were constructed and then stored in an NPM package. Each of these JSON objects then had an associated 'Async' version created. The index file of the package imports these data objects and exports them in a collection called “Data”. These mockup files make up the garmin-data package. Models Generated With JSON Crack The garmin-mockups package imports the files above and goes through each attribute generating artificial (new) data using proprietary functions, such as those found in the utils package. For example, with the EpochsData object:
Use case ideas
Explore entirely new use cases
Ideas to combine with some other data sources
Open-source data library We welcome contributions and forks to this data set, and look forward to seeing what developers build in our Liberty. Equality. Data. Slack channel. Considerations for next version/improvements
Join our Slack community; Liberty. Equality. Data. to brainstorm and collaborate with other app developers, designers, and our team.
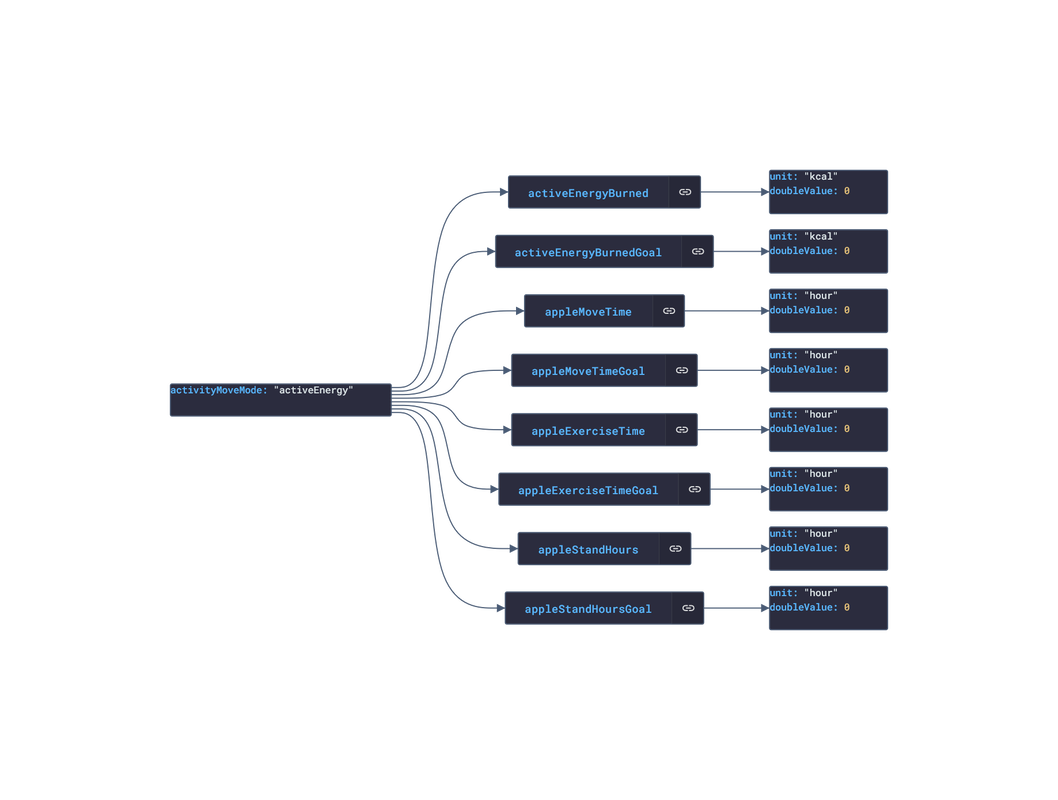
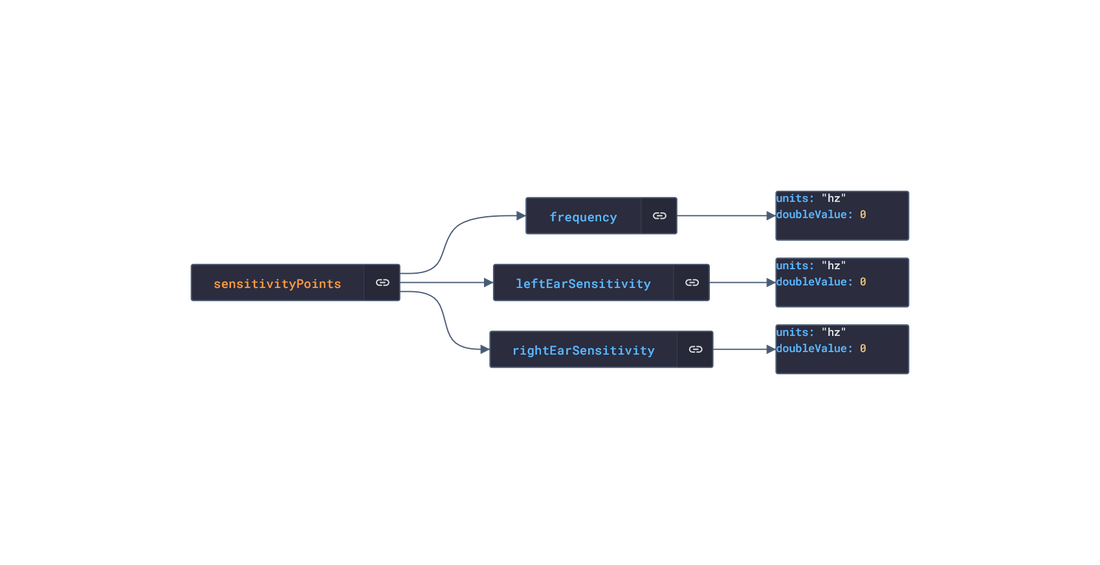
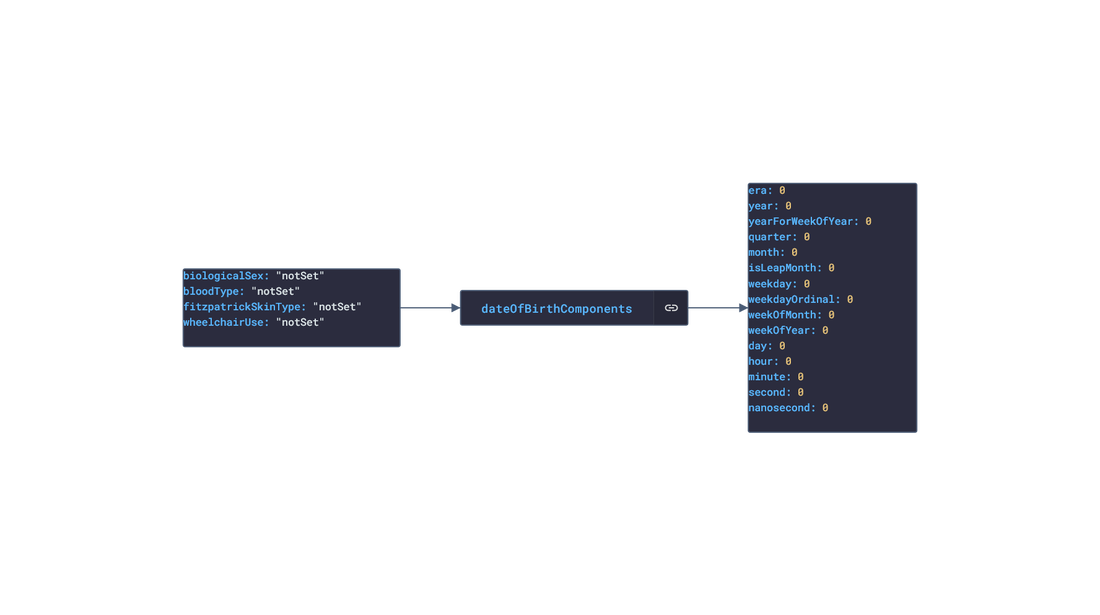
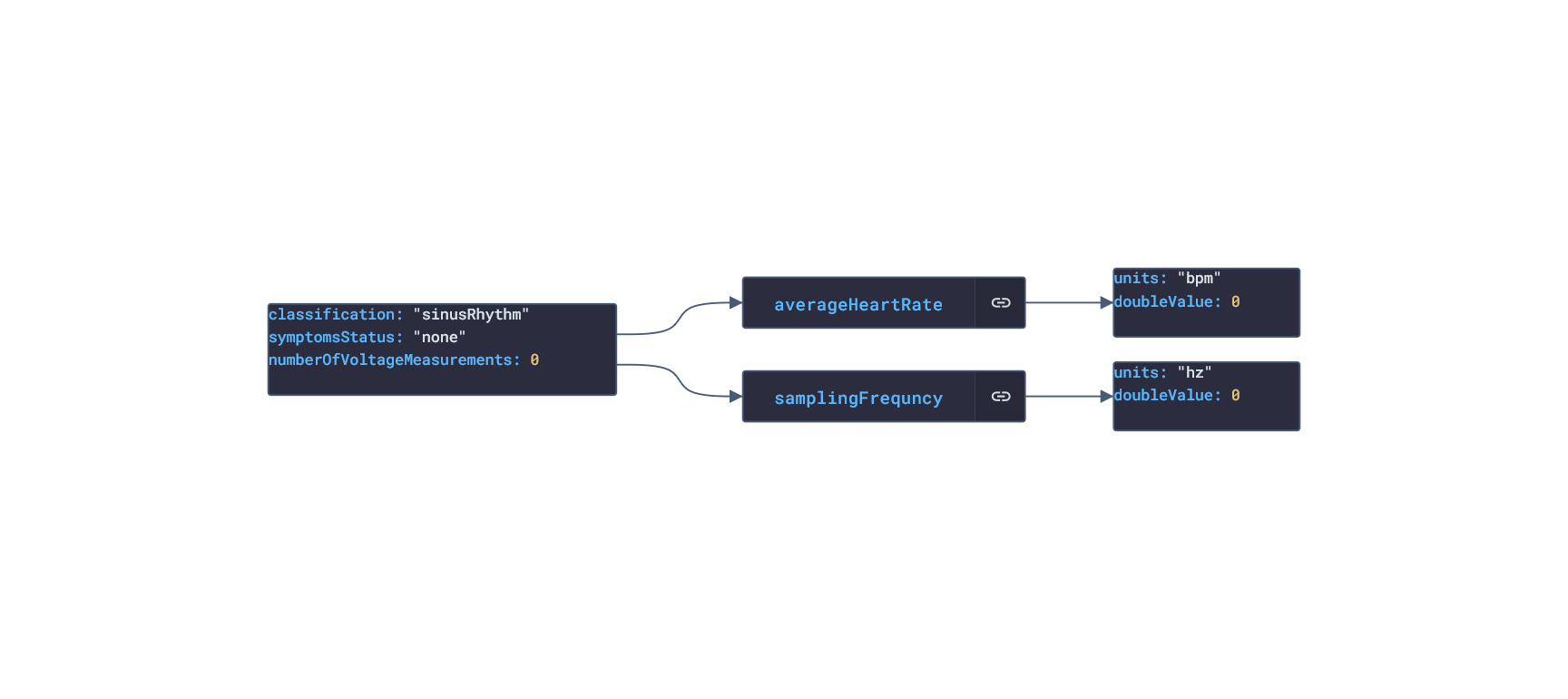
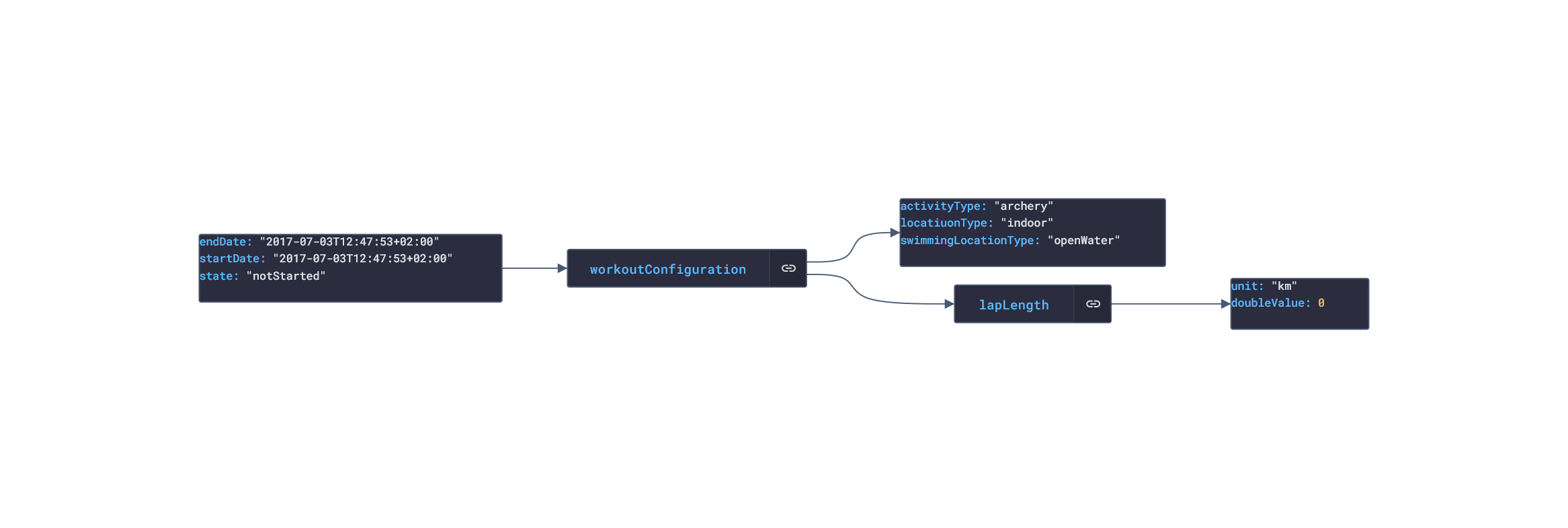
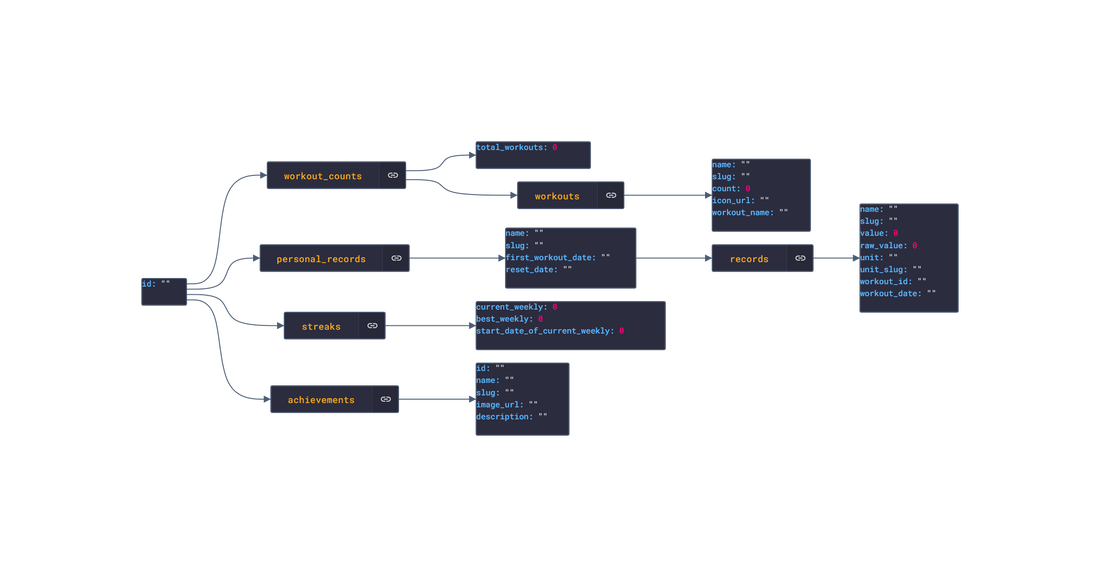
In this post, we are going deeper into the Dynamic Data project, looking at the iOS Healthkit dynamic data (library available here on GitHub and at NPM). Opening the library, you’ll see there are nine types of data objects: HKActivitySummary, HKAudiogramSample, HKCharacteristic, HKClinicalRecord, HKElectrocardiogram, HKWorkoutConfiguration, HKWorkoutSession, HKWorkoutRoute, and HKWorkouts. Learn more about dynamic data generators and the benefits of artificial data in software development.  About the data source Apple's HealthKit is a framework that allows developers to create health and fitness apps for the iPhone and iPad. It provides a set of data objects that can be used to represent various types of health and fitness data, including information about a person's physical activity, sleep patterns, nutrition, and medical history. HealthKit gathers data from a wide range of sources, including sensors in Apple devices, such as the accelerometer and gyroscope, as well as third-party apps and devices that are compatible with HealthKit. For example, a person might use a fitness tracker to track their workouts and sync the data with HealthKit or a sleep tracking app to monitor their sleep patterns and sync the data with HealthKit. The Apple Health app is a pre-installed app on Apple devices. It integrates with the HealthKit framework, which allows it to gather data from a wide range of sources, including sensors in Apple devices, such as the accelerometer and gyroscope, as well as third-party apps and devices that are compatible with HealthKit. Overall, HealthKit is designed to provide a centralized repository for a person's health and fitness data, allowing them to track their progress and make informed decisions about their health and wellness. Approach used Apple provides developer documentation of the Healthkit framework. By inspecting the vital data, several JSON objects were constructed that are then stored in an NPM package. The index file of the package imports these data objects and exports them in a collection called “Data”. These mockup files make up the ios-health-data package. Models Generated With JSON Crack The ios-health-mockups package imports the files above and goes through each attribute generating artificial (new) data using proprietary functions, such as those found in the utils package. For example, with the HKActivitySummary object:
Use case ideas
Explore entirely new use cases
Ideas to combine with some other data sources
Open-source data library We welcome contributions and forks to this data set, and look forward to seeing what developers build in our Liberty. Equality. Data. Slack channel. Considerations for next version/improvements
Join our Slack community; Liberty. Equality. Data. to brainstorm and collaborate with other app developers, designers, and our team.
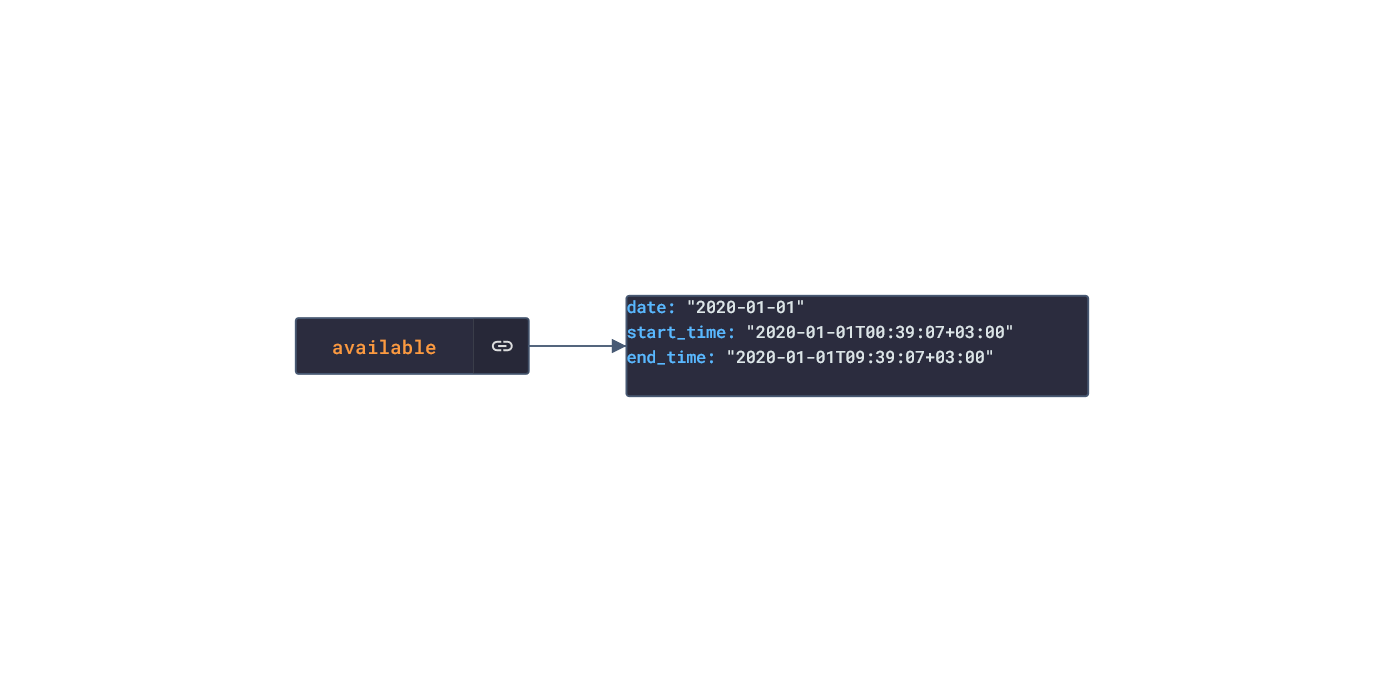
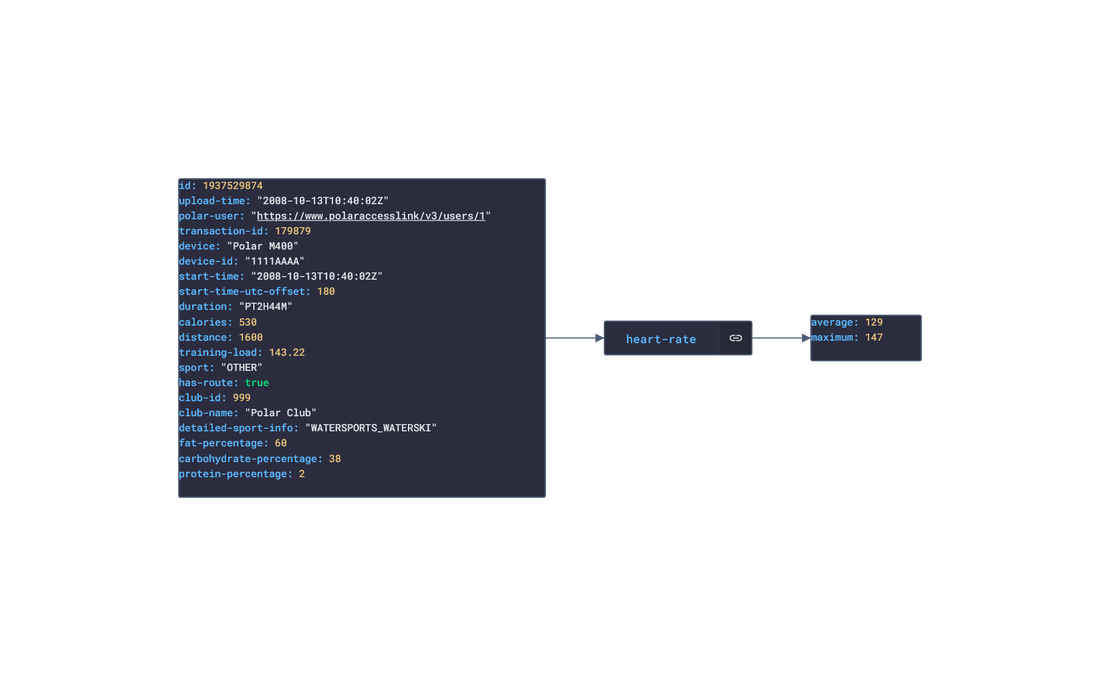
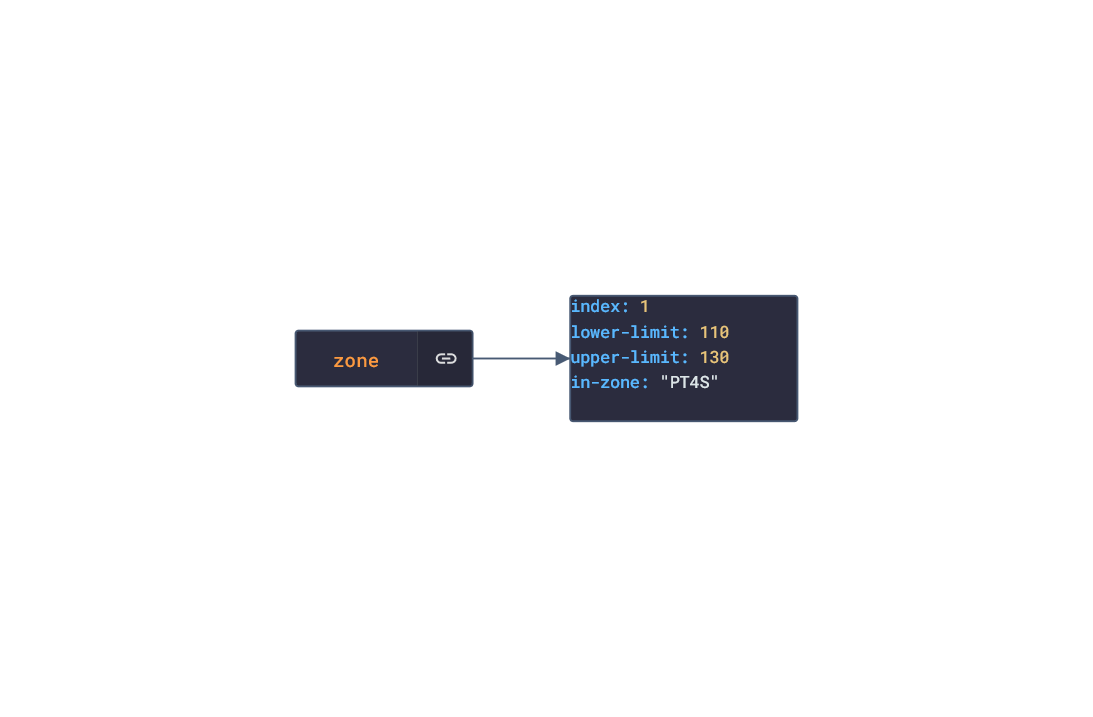
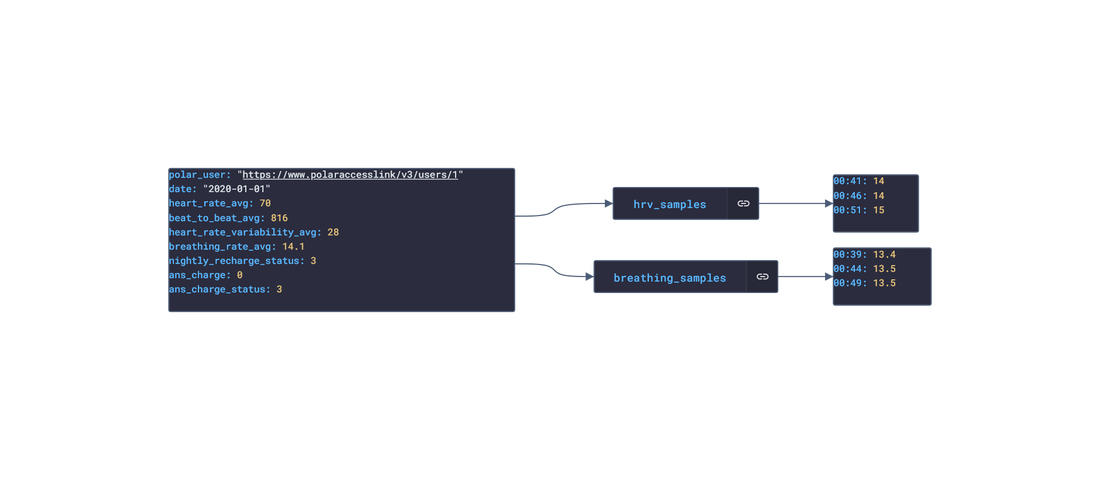
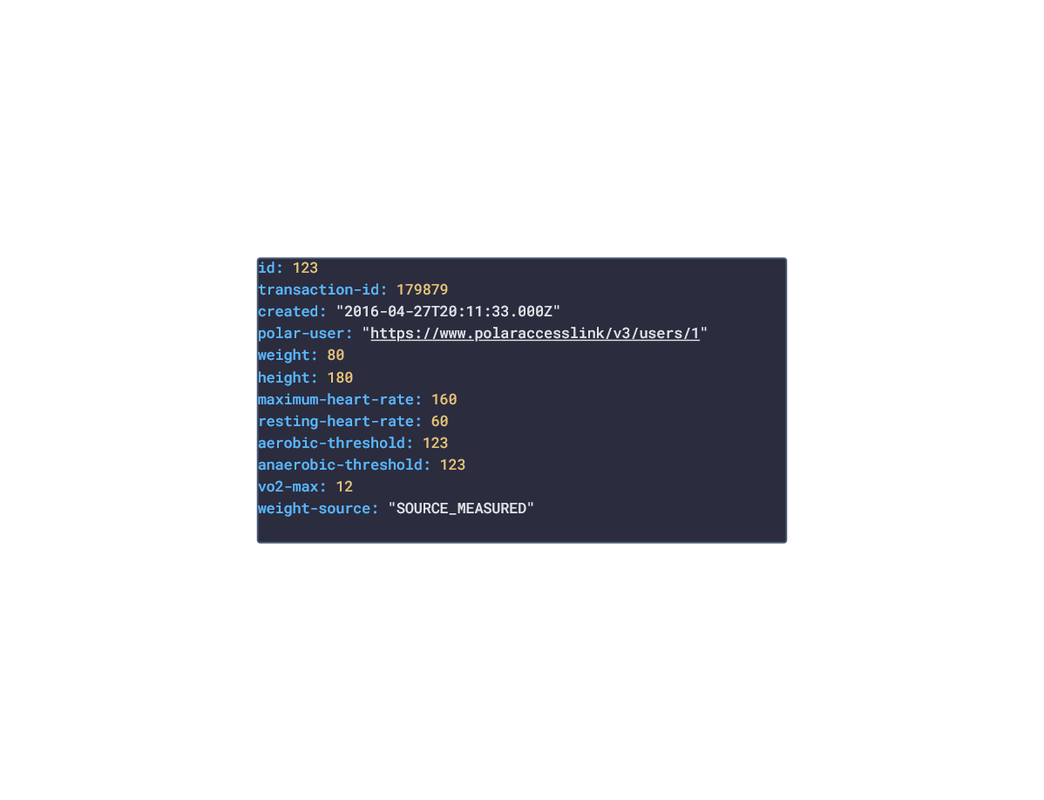
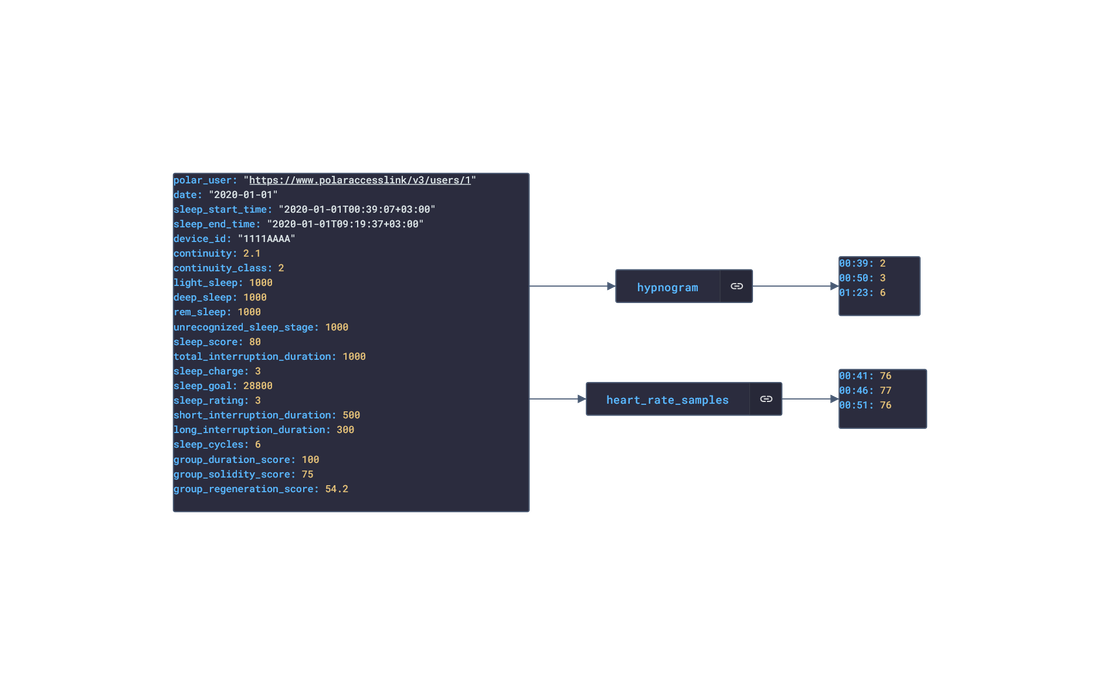
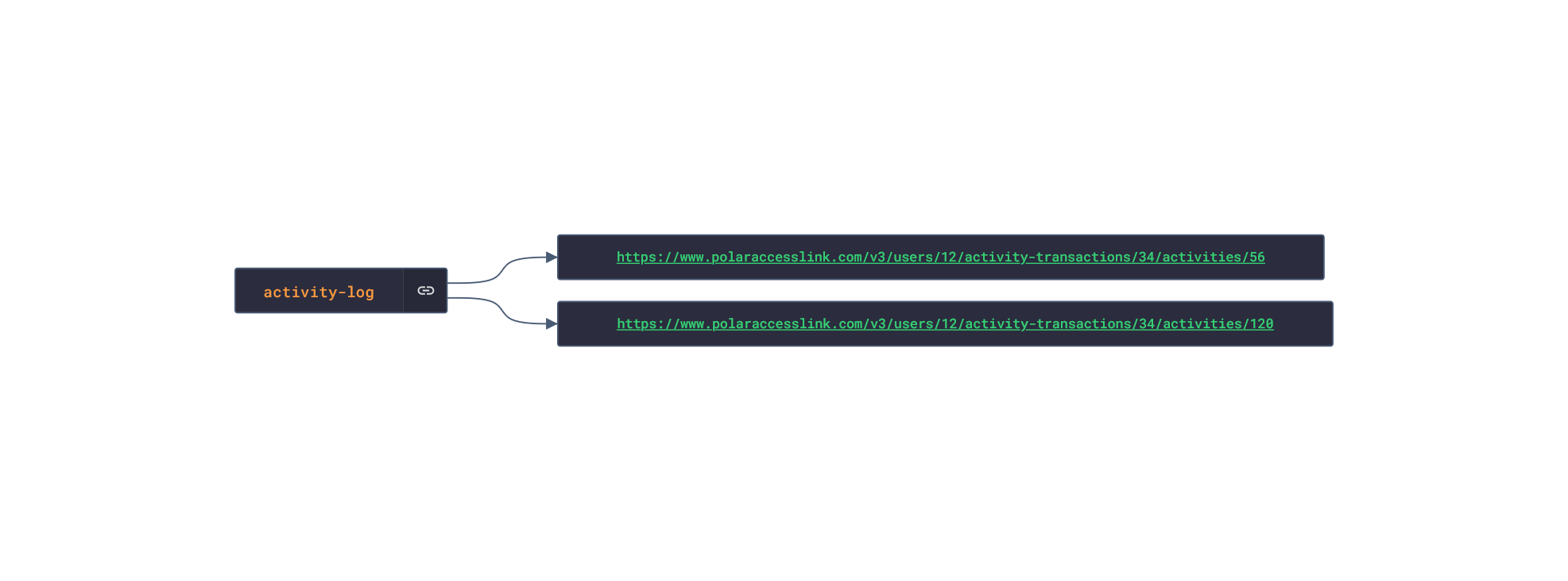
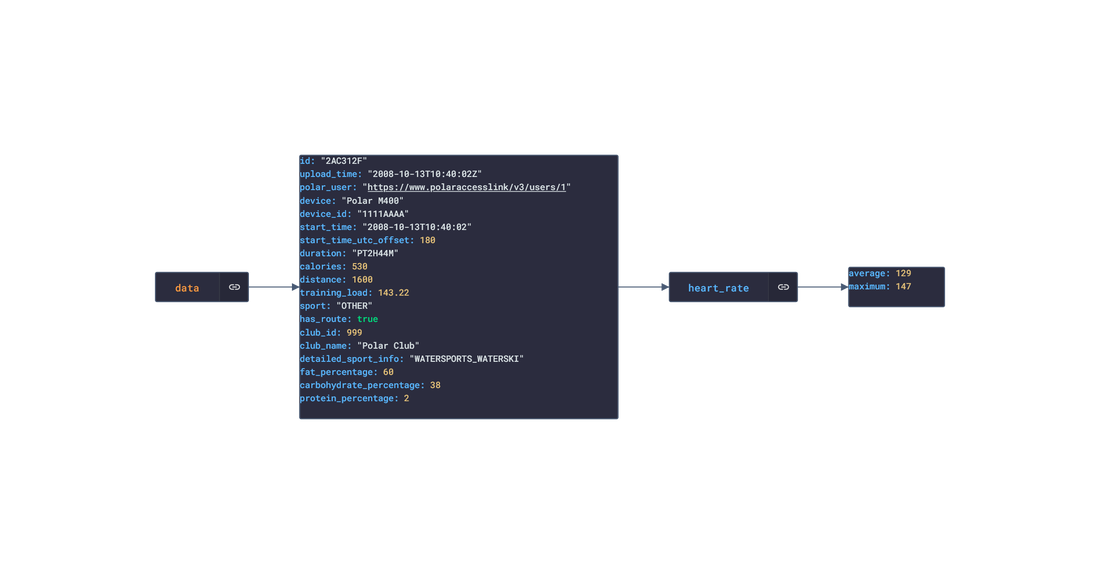
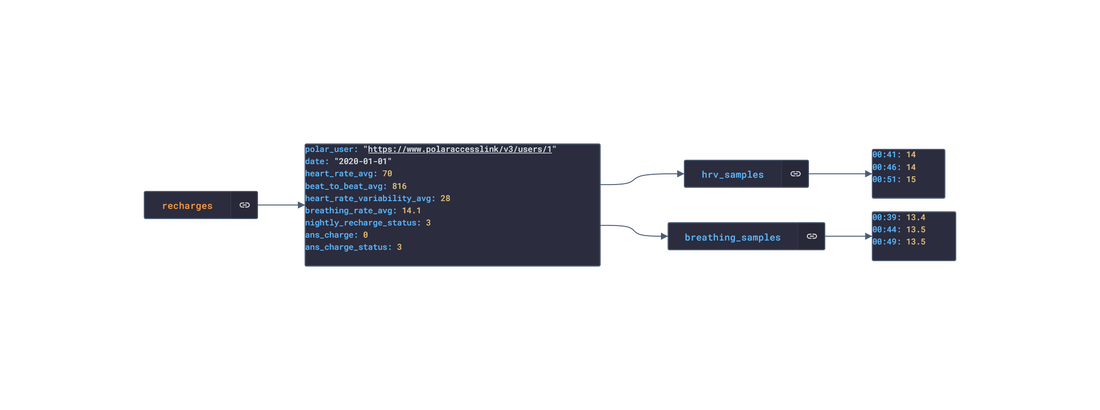
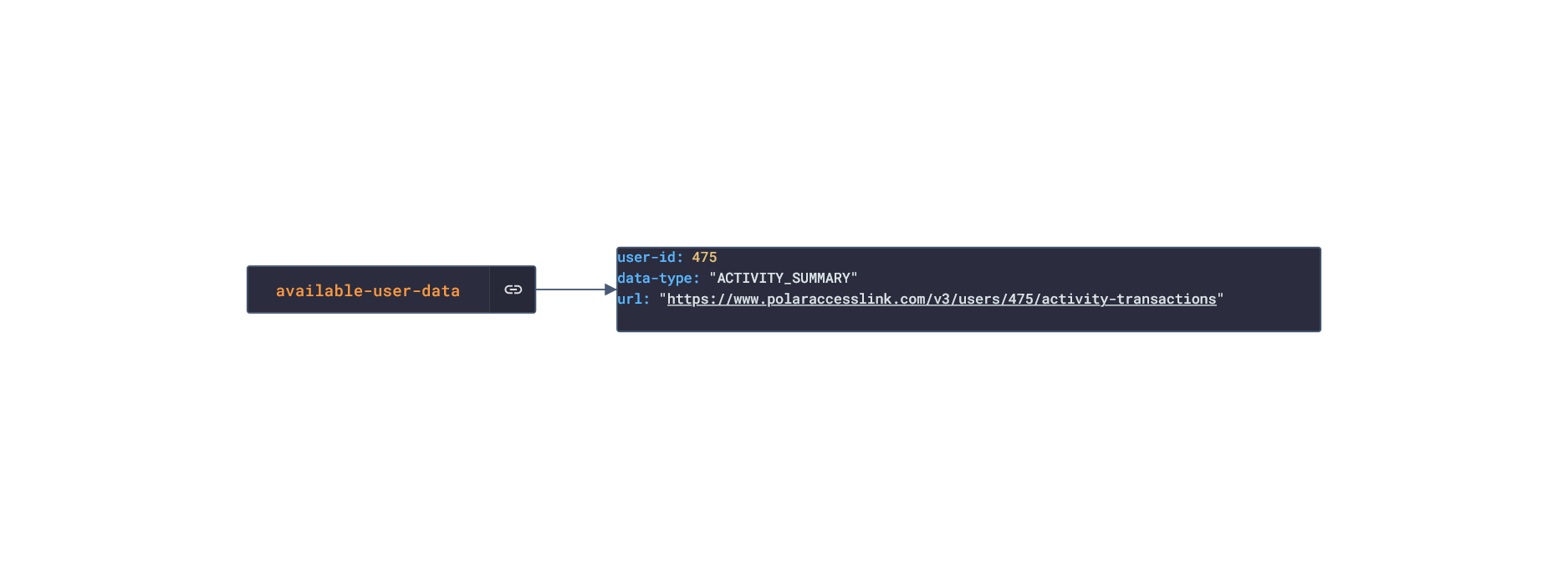
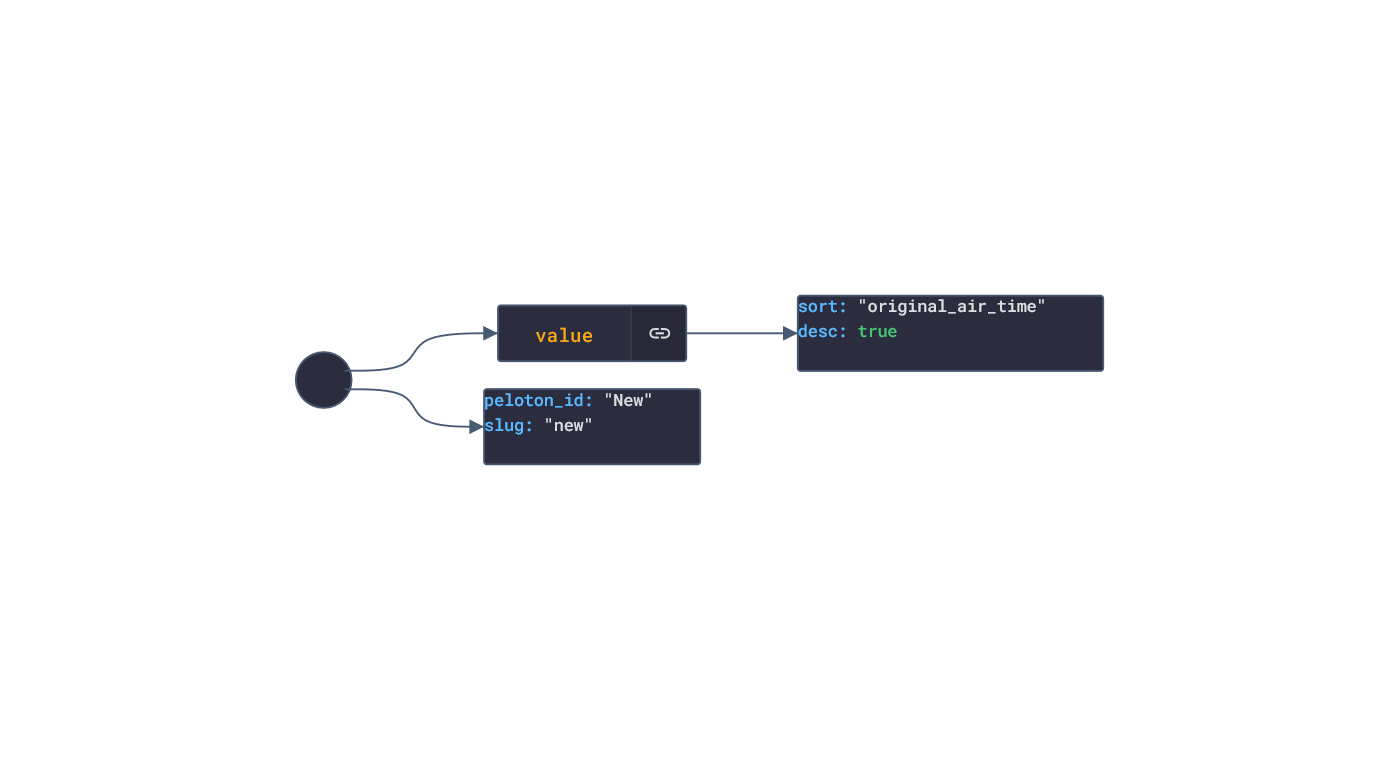
In this post, we are going deeper into the Dynamic Data project, looking at the Polar dynamic data (library available here on GitHub and at NPM). Opening the library, you’ll see there are twenty one types of data objects: getActivitySummary, getAvailableSamples, getAvailableSleepTimes, getExercise, getExerciseSummary, getHeartRateZones, getNightlyRecharge, getPhysicalInfo, getSamples, getSleep, getStepSample, getUserInfo, getWebhook, getZoneSample, listActivities, listExercises, listNightlyRecharge, listNotifications, listPhysicalInfo, listSleep, and listTrainingExercises. Learn more about dynamic data generators and the benefits of artificial data in software development.  About the data source Polar (iOS|Android) is a fitness-tracking company offering various models of several fitness watches and sensors. The data traccked from these devices include:
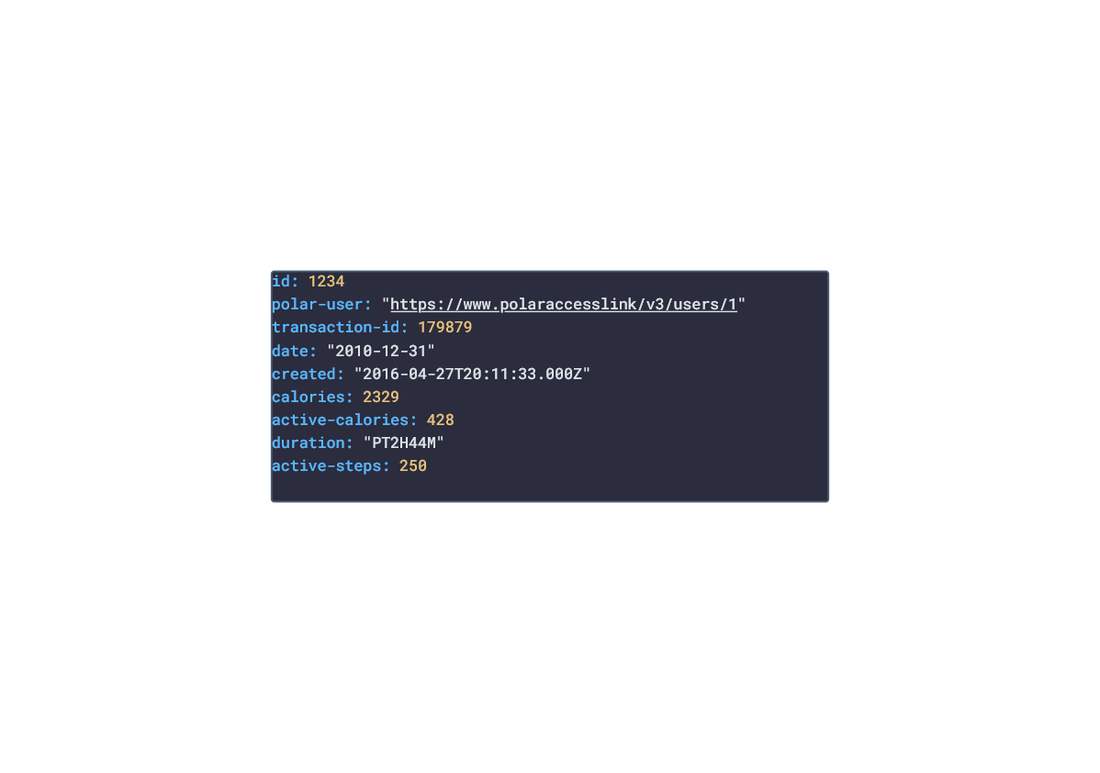
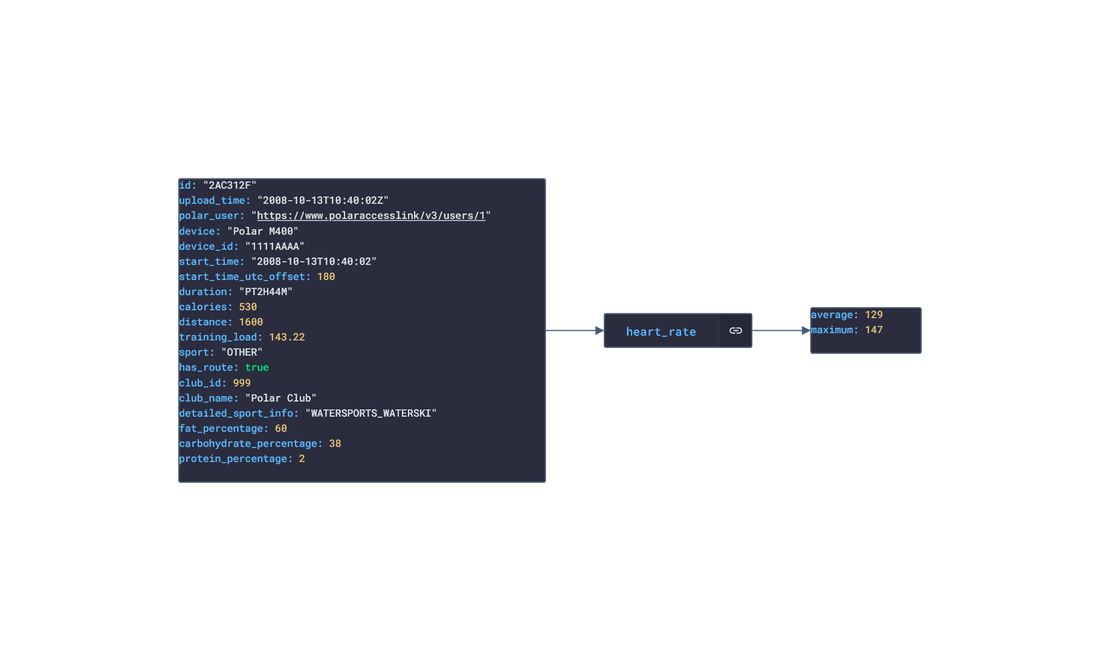
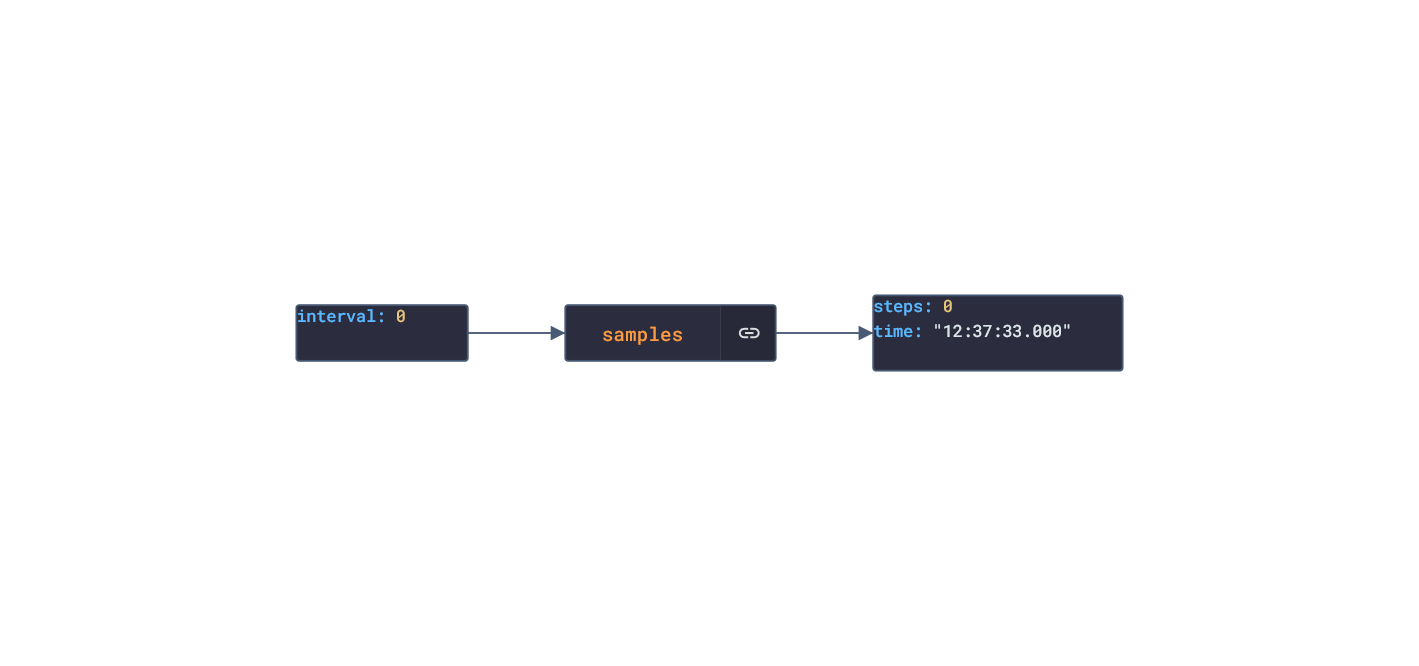
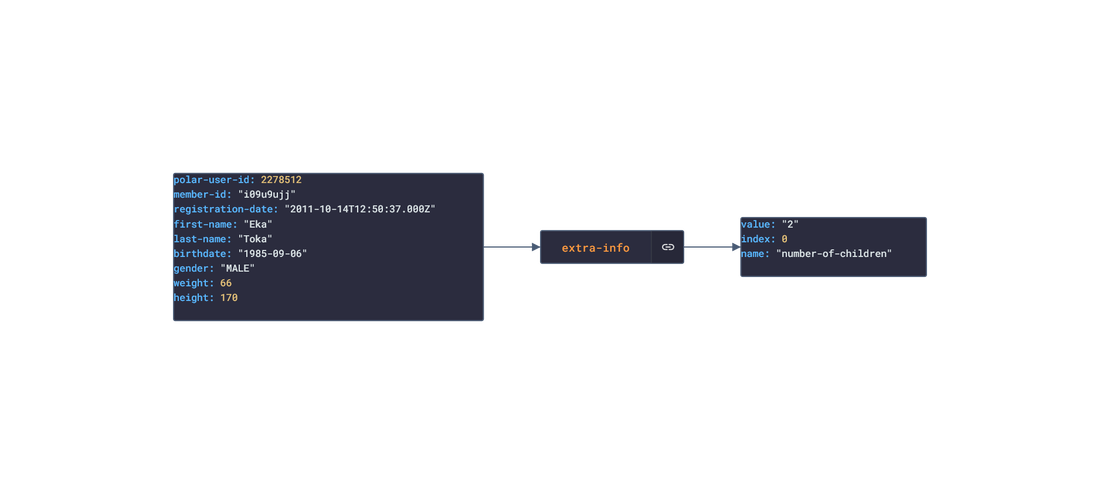
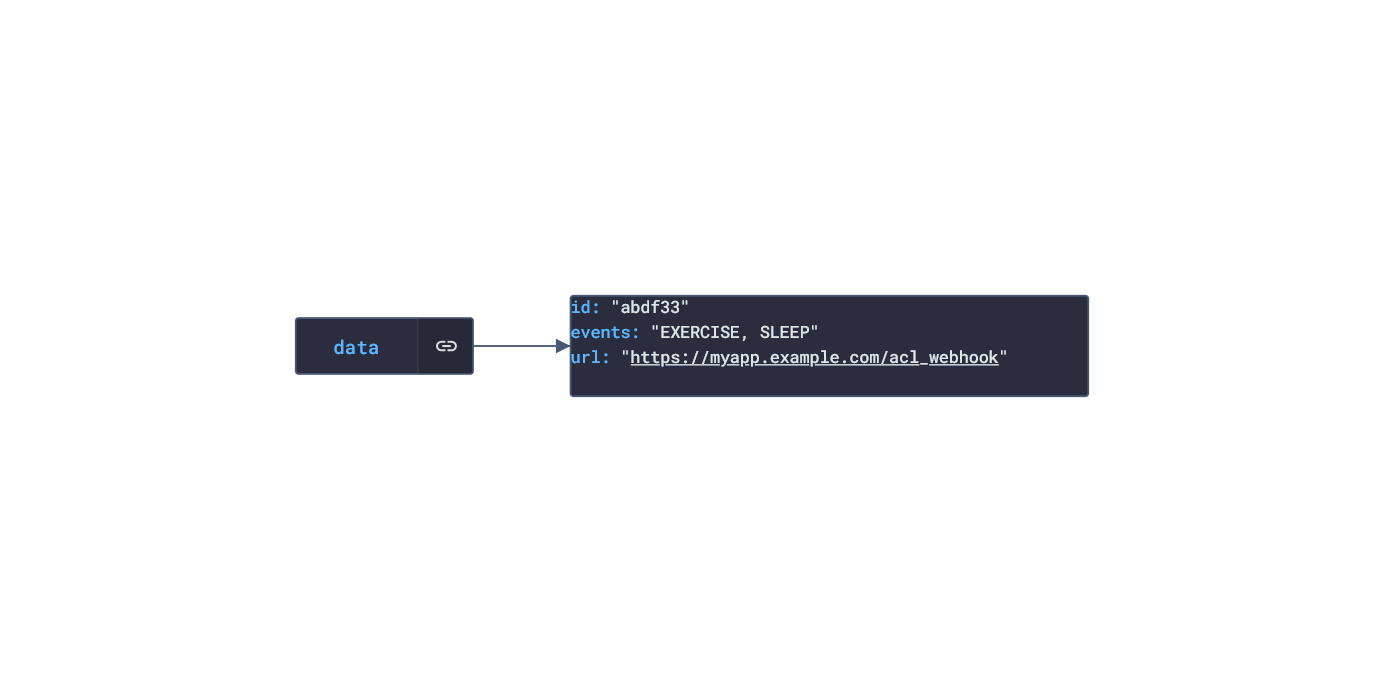
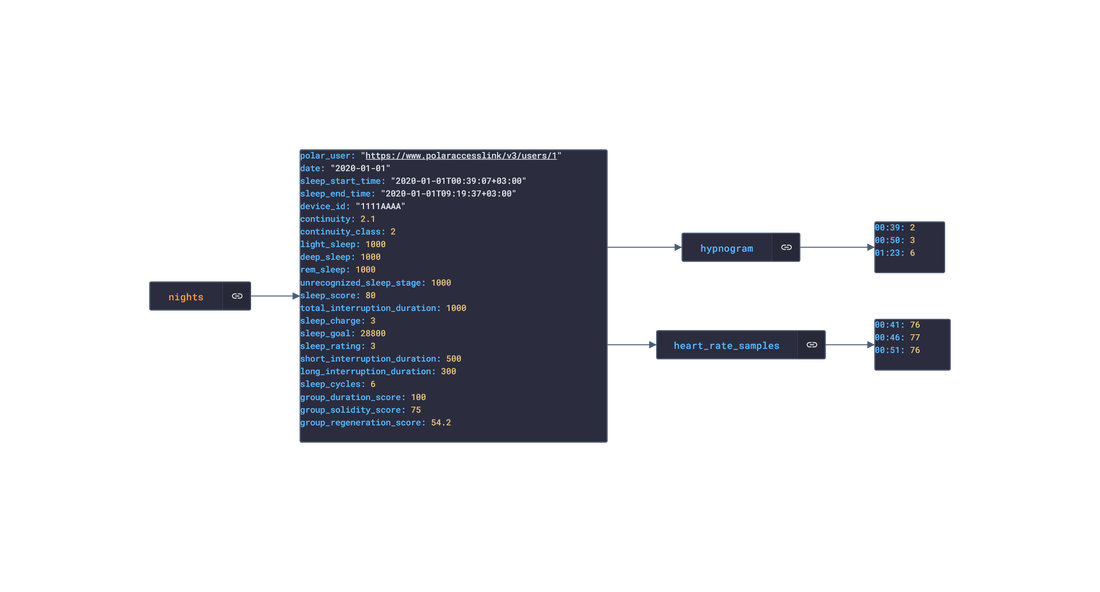
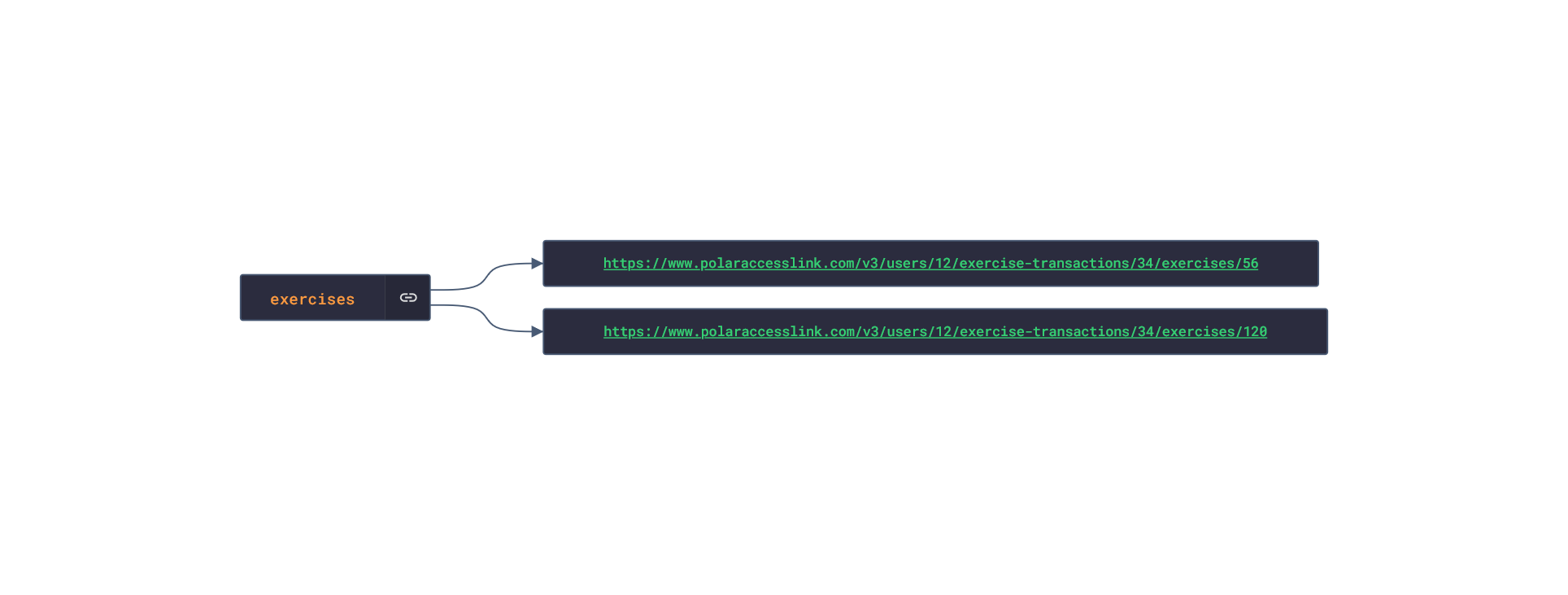
Polar offers a free app, Polar Flow, on the app stores that analyze the data retrieved from their products. The main features offered by the app are Training and Activity tracking. Training tracking allows the user to create a workout reigment with set goals and targets and analyze their performnce of their training session. Activity tracking shows an overview of the data (calories burnt, heart rate, steps, etc) captured over any 24-hour period. 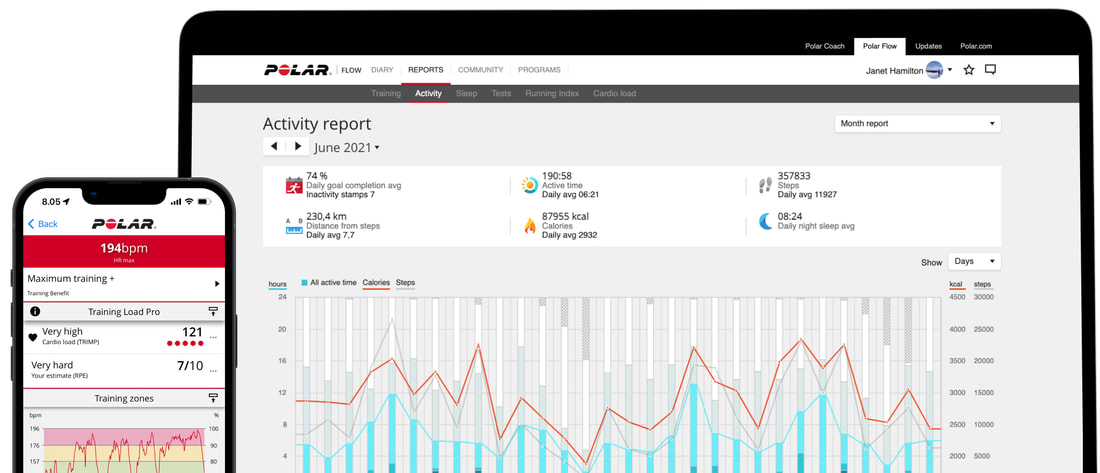 Approach used Polar has an API that grants access to the user's dataset. These requests generate JSON objects that are then stored in an NPM package. The index file of the package imports this data object and exports it in a collection called “Data”. These mockup files make up the polar-data package. Models Generated With JSON Crack The polar-mockups package imports the files above and goes through each attribute generating artificial (new) data using proprietary functions, such as those found in the utils package. For example, with the getSamples object:
Use case ideas
Ideas to combine with some other data sources
Open-source data library We welcome contributions and forks to this data set, and look forward to seeing what developers build in our Liberty. Equality. Data. Slack channel. Considerations for next version/improvements
With Prifina developers can use the Dynamic Data Libraries natively in the App Studio to build direct to consumer apps where individuals can run them with their own user-held data. Join our Slack community; Liberty. Equality. Data. to brainstorm and collaborate with other app developers, designers, and our team.
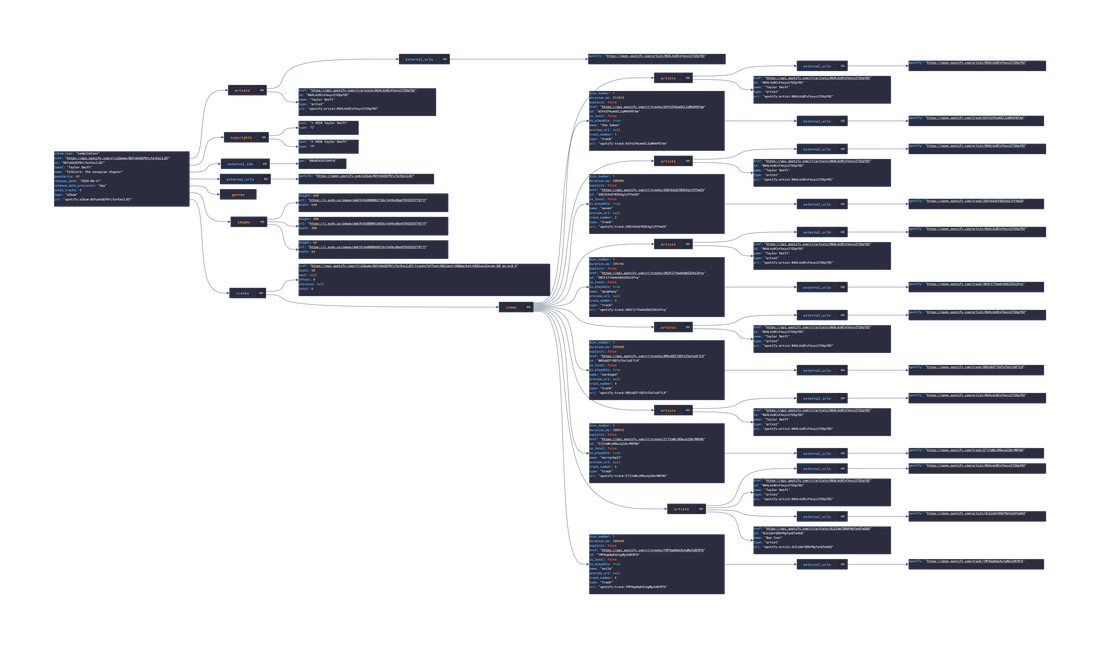
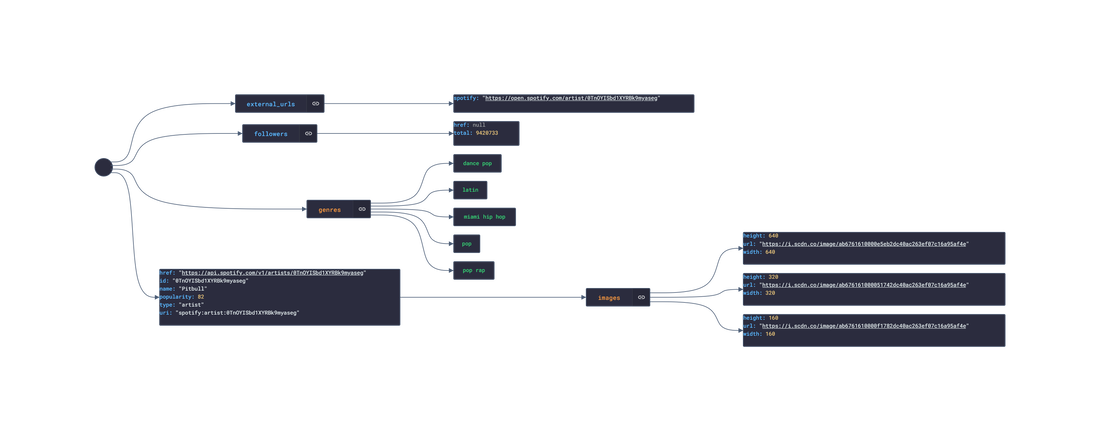
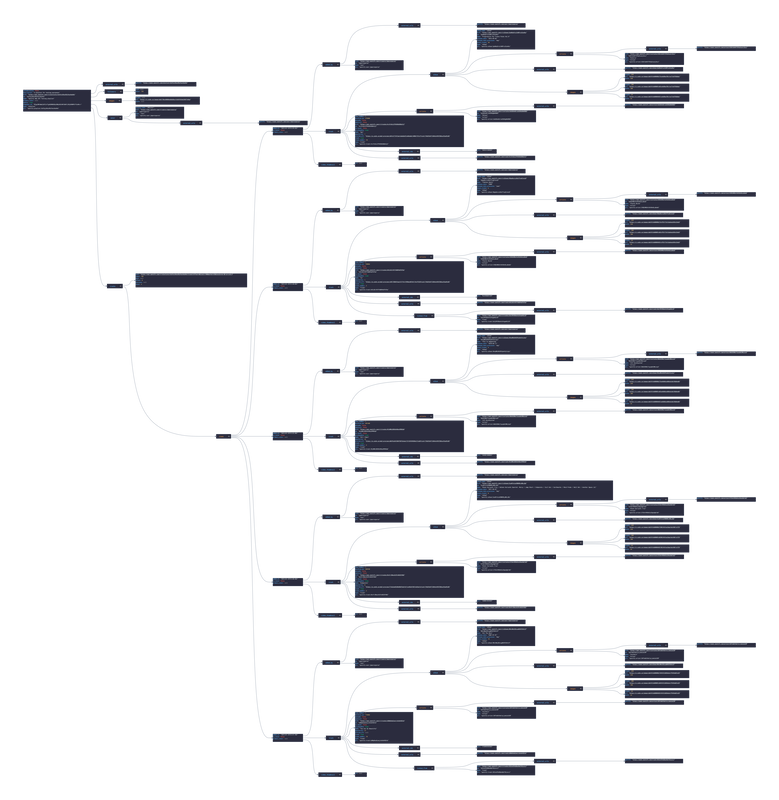
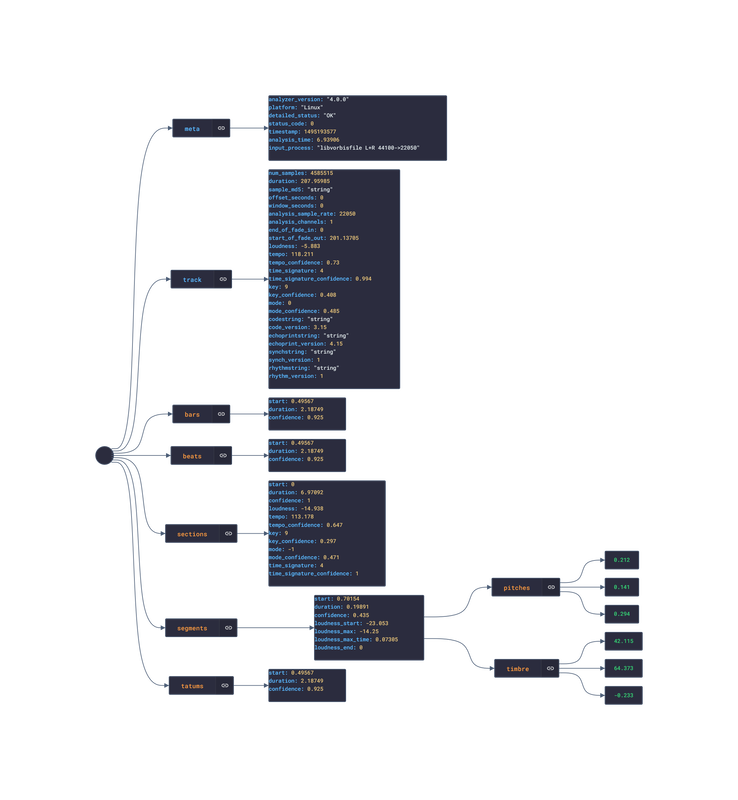
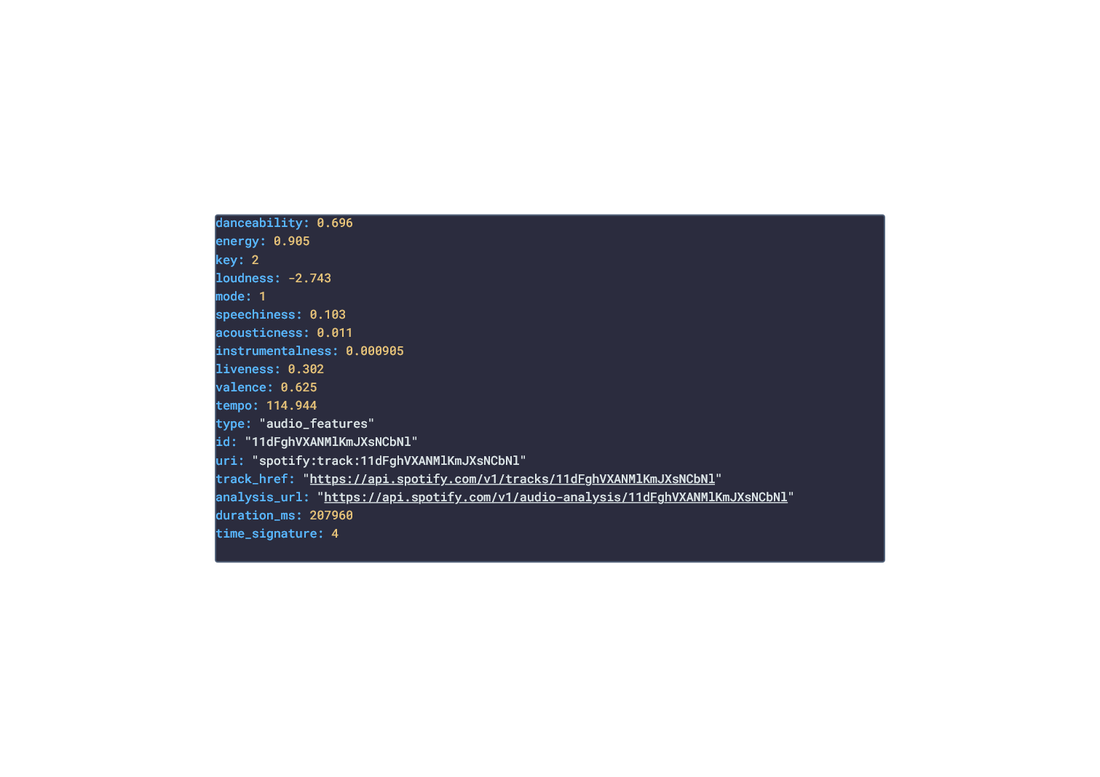
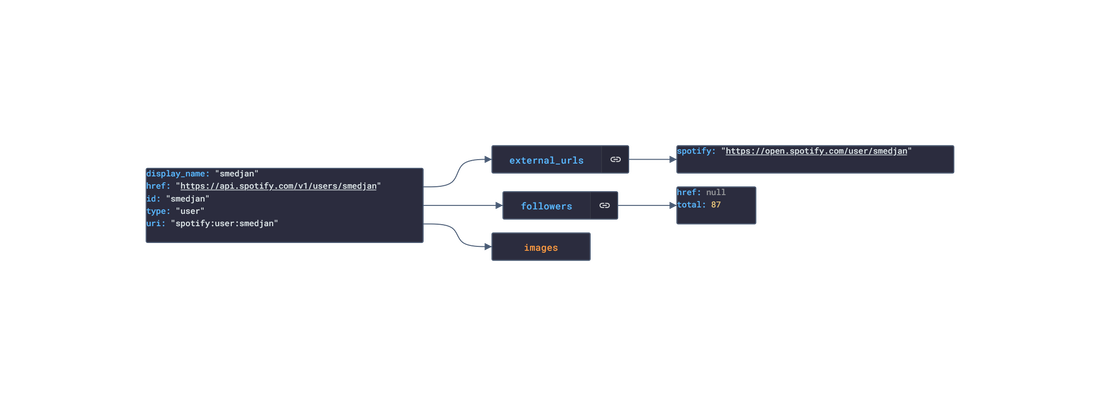
In this post, we are going deeper into the Dynamic Data project, looking at the Spotify dynamic data (library available here on GitHub and at NPM). Opening the library, you’ll see there is one type of data object: Album, Artist, ArtistRelatedArtists, ArtistTopTracks, Episode, Playlist, Shows, Track, TrackAudioAnalysis, TrackAudioFeatures, and UserProfile. Learn more about dynamic data generators and the benefits of artificial data in software development. About the data source Spotify (iOS|Android) is the market leader in digital Music Streaming, offering users the option to stream audiobooks, music, and podcasts from Spotify's wide catalogue featuring millions of songs across the genre spectrum. The user can add any song they enjoy to one of their playlists. Additionally, the user can like songs, ablums, artists, and playlists to quickly replay them. AI recommendations are also suggested through Radios (a list of songs similar to the song,artist,album or playlist selected) and Mixes (a daily generated list of songs similar to a group of songs liked in the past). The app is free and ad-supported however, Spotify offers a Premium subscription service that offers the user the option to download music locally for offline listening, ad-free, unlimited skipping, and more.  Approach used Spotify has an API that grants access to its entire catalogue of audiobooks, music and podcasts, and the user’s preferences to that catalogue: saved audiobooks, episodes, music, playlist, genres, etc. These requests generate JSON objects that are then stored in an NPM package. The index file of the package imports this data object and exports it in a collection called “Data”. These mockup files make up the spotify-data package. Models Generated With JSON Crack The spotify-mockups package imports the files above and goes through each attribute generating artificial (new) data using proprietary functions, such as those found in the utils package. For example, with the UserProfile object:
Use case ideas
Ideas to combine with some other data sources
Open-source data library We welcome contributions and forks to this data set, and look forward to seeing what developers build in our Liberty. Equality. Data. Slack channel. Considerations for next version/improvements
With Prifina developers can use the Dynamic Data Libraries natively in the App Studio to build direct to consumer apps where individuals can run them with their own user-held data. Join our Slack community; Liberty. Equality. Data. to brainstorm and collaborate with other app developers, designers, and our team.
Motivational Quotes powered Oura Have you ever dreamed of training with a wise old Shaolin monk that would give you the right motivational quotes to go pursue your work out? Well, we do not provide this service at Prifina but one of our Community Creator decided to build a widget that would help you in the same way your Shaolin master would. How does it work?Nicolas Gonzalez built a widget that uses Oura data to present you motivational quotes that is determined by your health metrics. It uses Oura's readiness score to present its users with different motivational quotes. The Readiness score of Oura takes into account your recent activity, sleep patterns, heart rate, heart rate variability, body temperature and other body signals. The motivational quotes get generated by an API from API Ninja that fetches the quotes and presents you quotes that would push you to work out or to rest depending on your readiness score. For example, if your readiness score is below 74 meaning you are tired or that you slept less that 420 minutes, the quote generator would provide you a quote like "Your eyes water when you yawn because you miss your bed and it makes you sad". The widget also presents you with the most relevant daily active summary so you can have a more detailed analysis of your activity. How was the widget developed?The Widget itself is based on the common react component development for a SPA application. Nicolas started this widget by having the idea of using one of Prifina's data sources to keep users' motivated to accomplish their daily health goals. Nicolas had several ideas but decided to go with the one that seemed the most useful to him; reminding the user "how is my physical training going so far?". Starting from there he decided to seek for 3 party APIs that provided motivational quotes as a reference to the previous question. He tried to follow some sort of SOLID principle. However, as a design architect, he did not completely committed to this principle as the project wasn't as big as the projects you would usually use this approach with. The Experience of Nicolas
You won't learn Kung-fuThe widget might not give you the training a Shaolin master would but it gives you a good representation of how our community creators utilize user held data with the Prifina platform to receive meaningful insights about yourself. Join our Slack community; Liberty. Equality. Data. to brainstorm and collaborate with other app developers, designers, and our team to build inventive application and widgets that uses user held data.
In this post, we are going deeper into the Dynamic Data project, looking at the Veri dynamic data (library available here on GitHub and at NPM). Opening the library, you’ll see there is one type of data object: Meal Activity. Learn more about dynamic data generators and the benefits of artificial data in software development.  About the data source Veri (iOS|Android) is a health tracking company that specializes in tracking how your body responds to different foods. This is achieved by their Continuous Glucose Monitors (CGM) that is applied to the back of the upper arm to measure blood sugar levels. Keeping your blood sugar level within the target range is good to prevent and delay serious health problems. The user can also upload their meal details, sleep and training data. It should be noted however that the CGM made by Veri should be used for medical purposes such as diabetes diagnosis, management or eating disorder diagnosis, etc. Approach used Veri provides a data-exporting service that allows the user to export a selection of their glucose values, meals, notes, training, sleep and flow scores. This results in a large CSV file of records, one of which were converted into a JSON object stored in a NPM package. The index file of the package imports this data object and exports it in a collection called “Data”. These mockup files make up the veri-data package 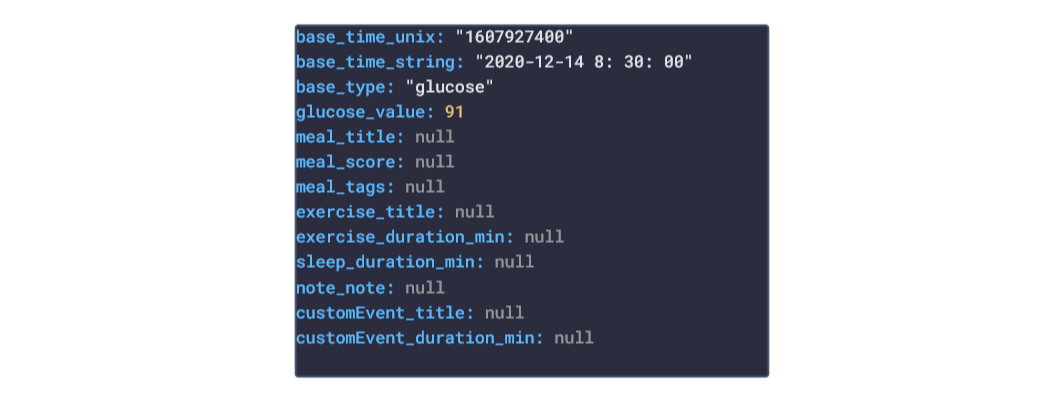 Models Generated With JSON Crack The veri-mockups package imports the files above and goes through each attribute generating artificial (new) data using proprietary functions, such as those found in the utils package. For example, with the mealActivity object:
Use case ideas
Ideas to combine with some other data sources
Open-source data library We welcome contributions and forks to this data set, and look forward to seeing what developers build in our Liberty. Equality. Data. Slack channel. Considerations for next version/improvements
With Prifina developers can use the Dynamic Data Libraries natively in the App Studio to build direct to consumer apps where individuals can run them with their own user-held data. Join our Slack community; Liberty. Equality. Data. to brainstorm and collaborate with other app developers, designers, and our team.
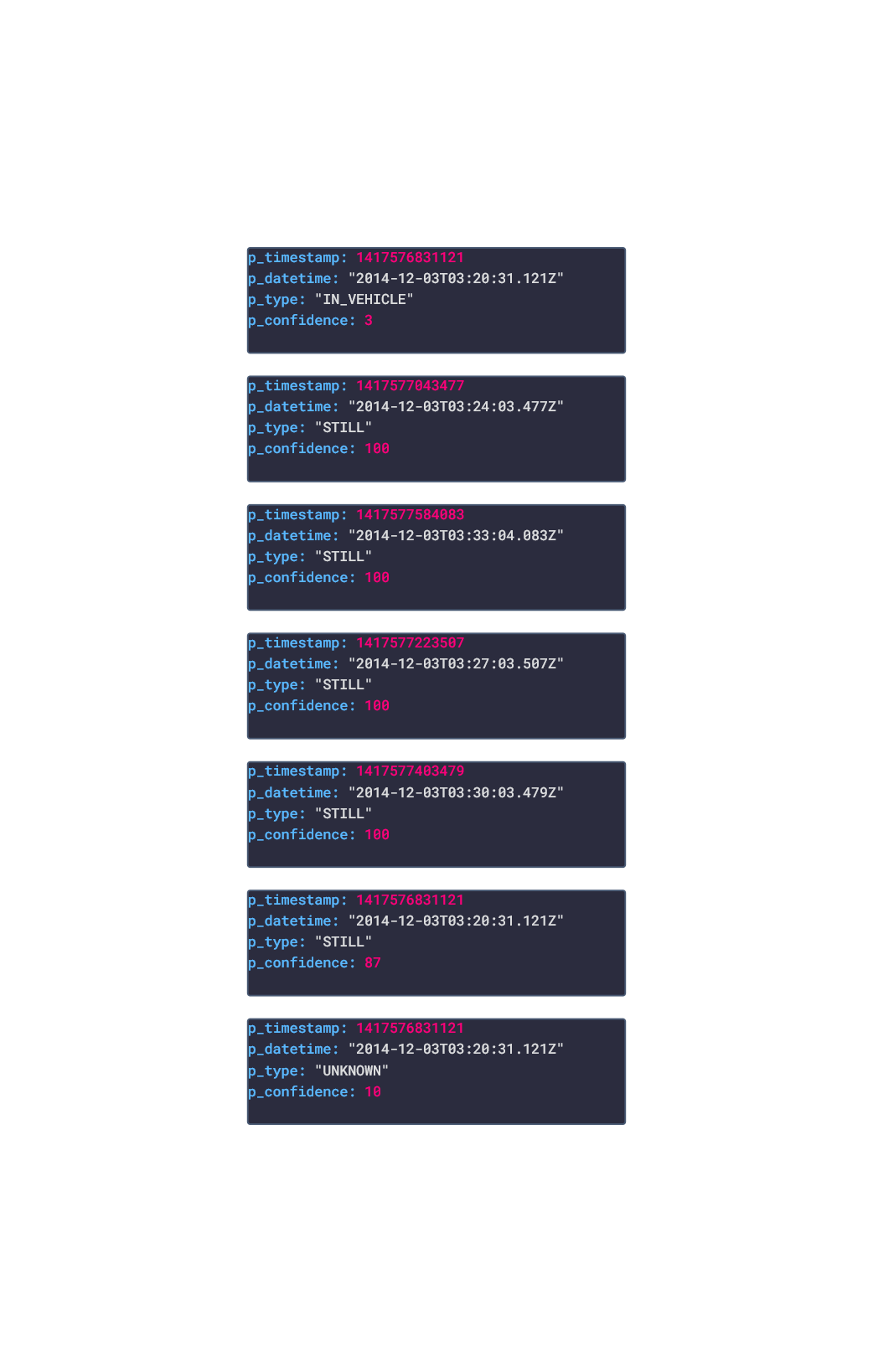
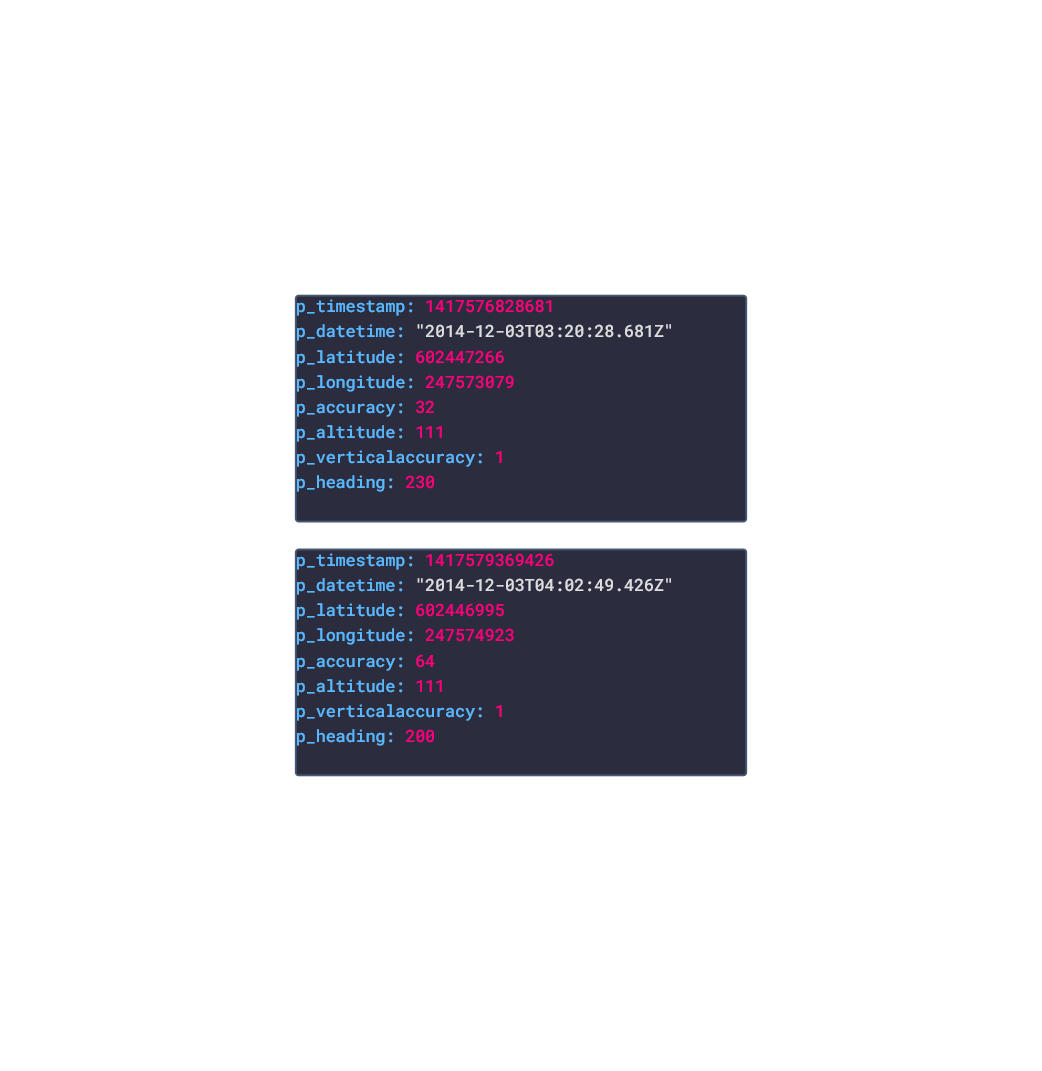
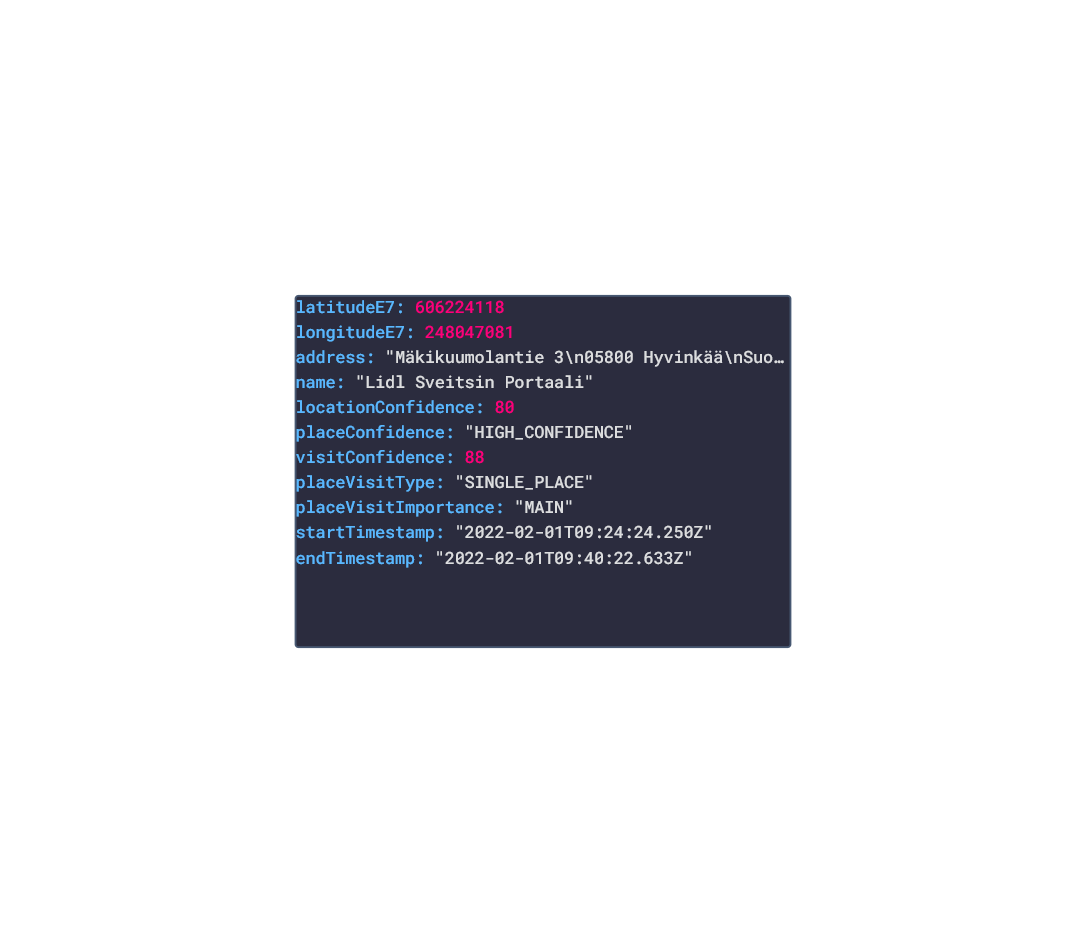
In this post, we are going deeper into the Dynamic Data project, looking at the Google Location dynamic data (library available here on GitHub and at NPM). Opening the library, you’ll see there are four types of data objects: Activity, Location, Places, Routes. Learn more about dynamic data generators and the benefits of artificial data in software development. Google Logo About the data source Google is one of the largest technology companies in the world, with several of their products being market leaders in their space such as YouTube (video sharing), Google.com (Search Engine), Google Maps (navigation), Google Chrome (web browsing), and much more. As a result, the data that Google can harvest from the user, and the user can request back from Google, is some of the richest available. For the purposes of this blog post, we would like to focus on the user's location history. Google Location History is an opt-in feature of a Google Account that tracks and stores the locations and routes visited, and the movement behavior of the users mobile phone, so long as the user:
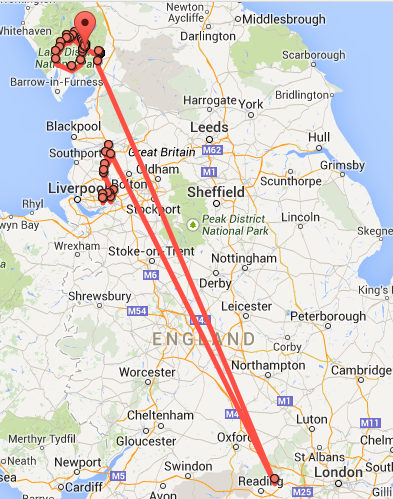 Example Image of Google Location History Approach used As stated in the above section, several JSON objects were exported from Google Takeout and stored in a NPM package. The index file of the package imports these data objects and exports them as a collection called “Data”. These mockup files make up the google-data package Models Generated With JSON Crack The google-mockups package imports the files above and goes through each attribute generating artificial (new) data using proprietary functions, such as those found in the utils package. For example, with the Route object:
Use case ideas
Ideas to combine with some other data sources
Open-source data library We welcome contributions and forks to this data set, and look forward to seeing what developers build in our Liberty. Equality. Data. Slack channel. Considerations for next version/improvements
With Prifina developers can use the Dynamic Data Libraries natively in the App Studio to build direct to consumer apps where individuals can run them with their own user-held data. Join our Slack community; Liberty. Equality. Data. to brainstorm and collaborate with other app developers, designers, and our team.
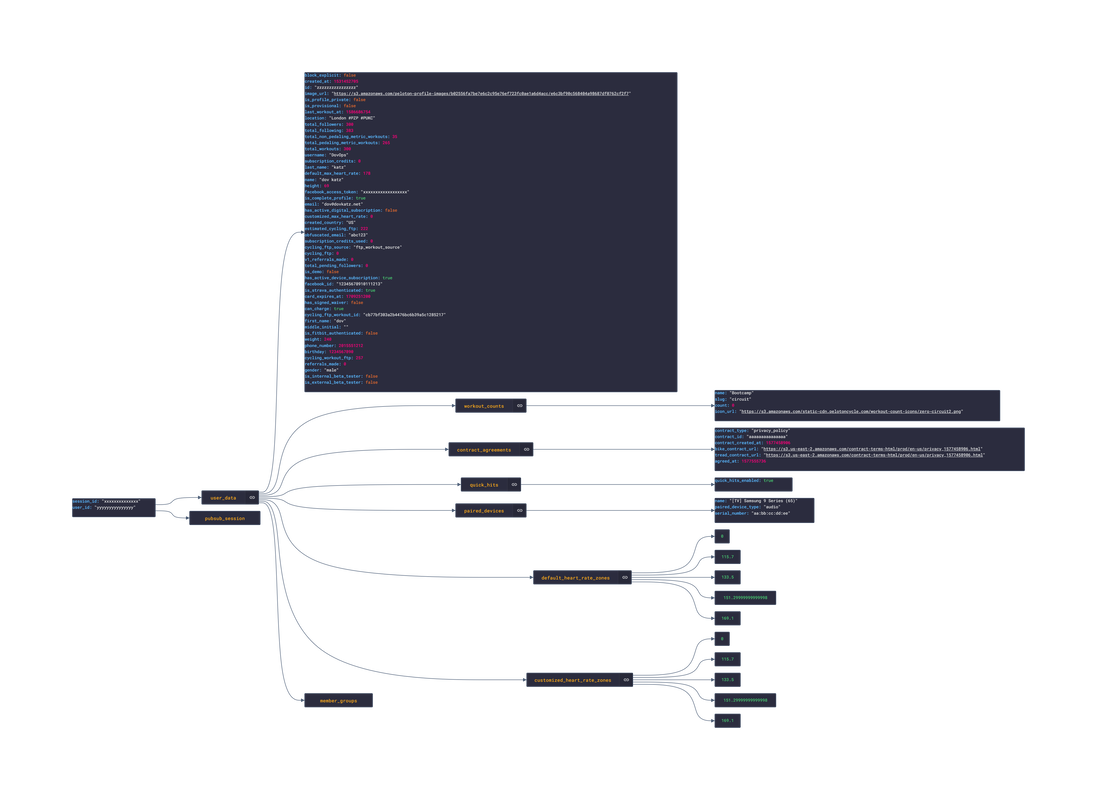
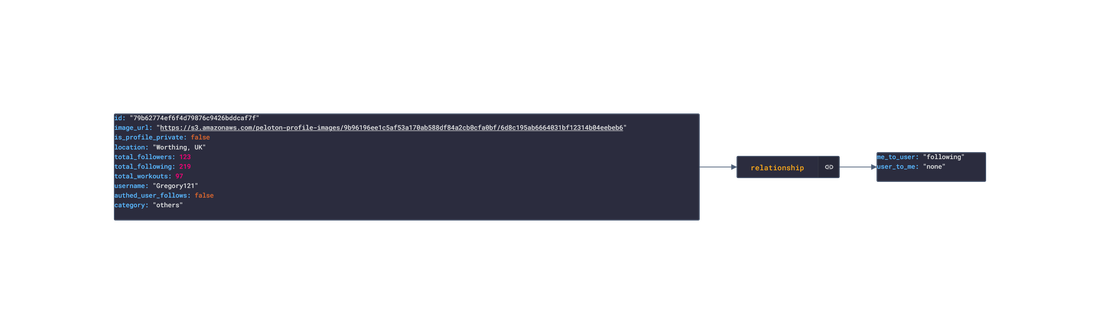
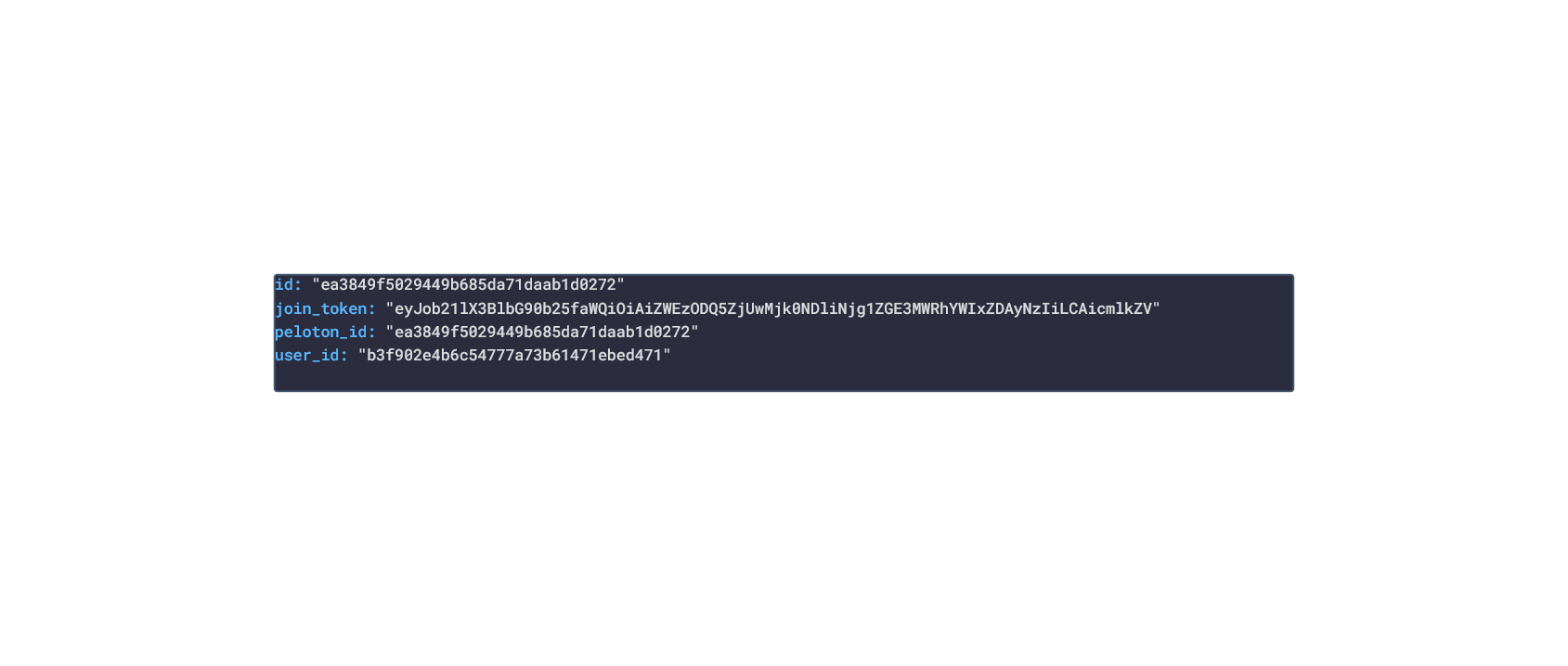
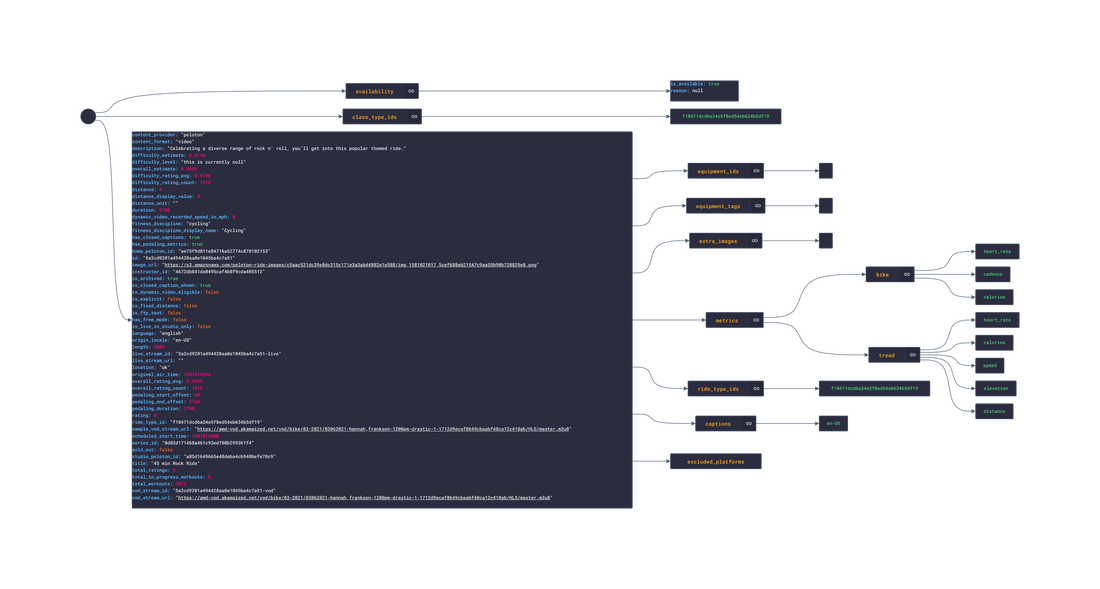
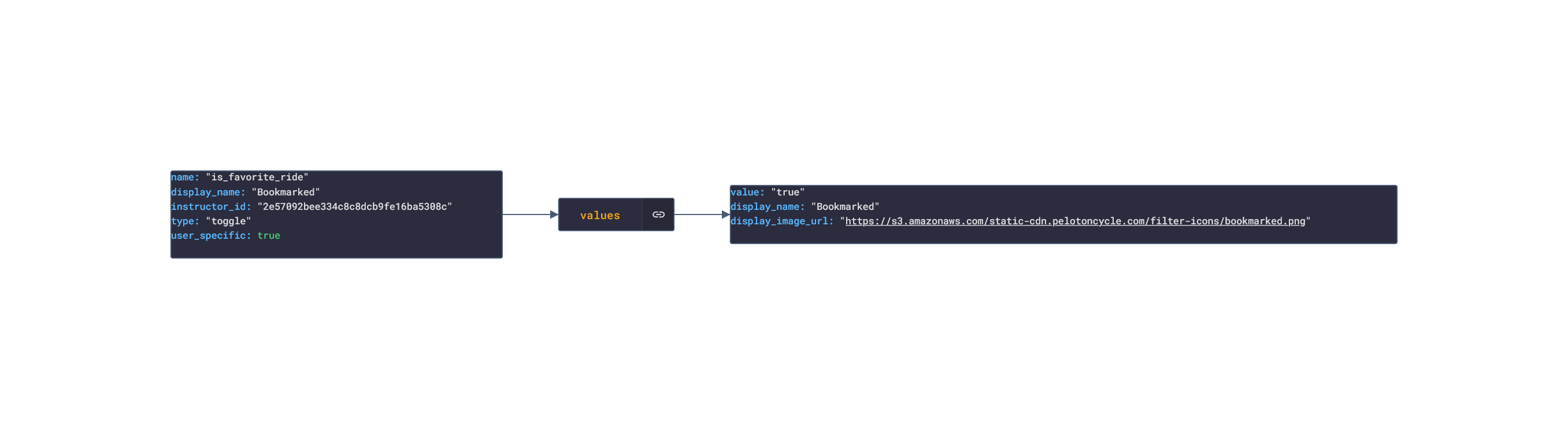
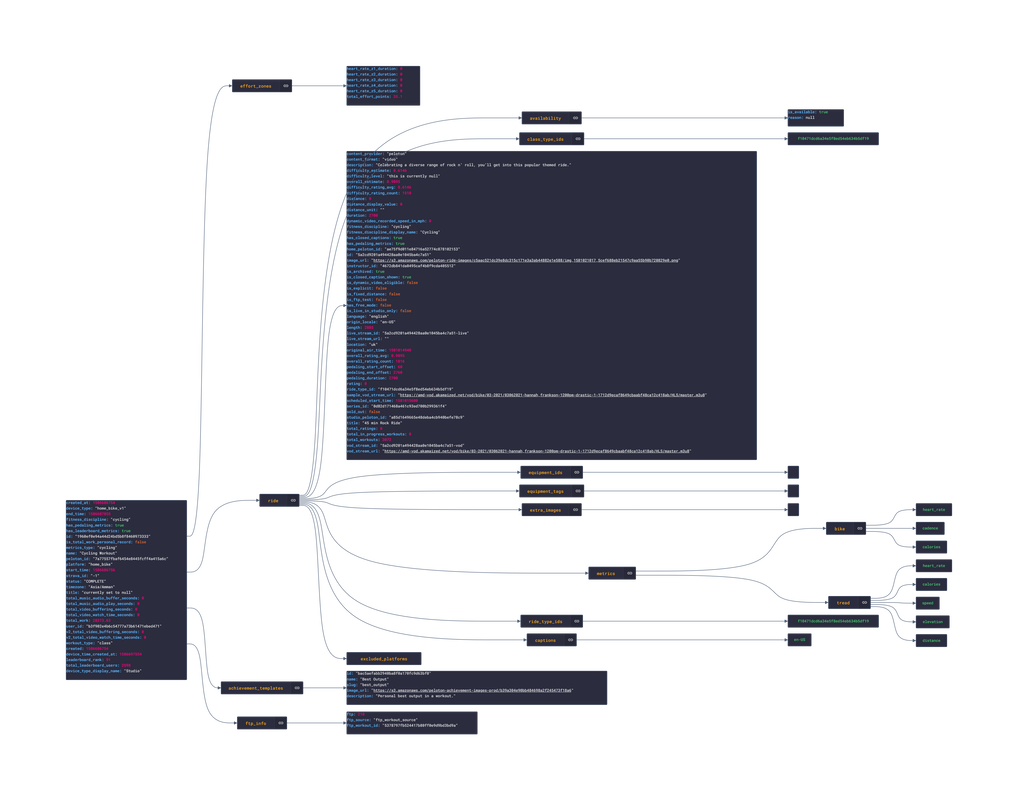
In this post, we are going deeper into the Dynamic Data project, looking at the Peloton dynamic data (library available here on GitHub and at NPM). Opening the library, you’ll see there are fourteen types of data objects: AchievementTemplate, AuthDetails, FacebookUserProfile, Instructor, Relationship, Reservation, RideDetails, RideFilter, RideSorts, UserData, UserOverview, UserProfile, UserSettings and WorkoutDetails Learn more about dynamic data generators and the benefits of artificial data in software development.  About the data source Peloton is a fitness company that makes exercise equipment, has an exercise app (IOS|Android) and creates workout videos. The types of equipment sold by Peloton include: Bikes, Treadmills, Rowing Machines, and a AI-powered Guide. Within the app, there are several classes that have workout videos that can be viewed:
 Example Peloton Product: Peloton Bike+ Approach used Peloton has an unoffical API that allows for the retrieval of workout and personal info. Using the API reference, several JSON objects were created and stored from the data types recorded. The index file of the package imports these data objects and exports them as a collection called “Data”. These mockup files make up the peloton-data package Models Generated With JSON Crack The peloton-mockup package imports the file above and goes through each attribute generating artificial (new) data using proprietary functions, such as those found in the utils package. For example, with the Reservation object:
Use case ideas
Ideas to combine with some other data sources Open-source data library We welcome contributions and forks to this data set, and look forward to seeing what developers build in our Liberty. Equality. Data. Slack channel. Considerations for next version/improvements
With Prifina developers can use the Dynamic Data Libraries natively in the App Studio to build direct to consumer apps where individuals can run them with their own user-held data. Join our Slack community; Liberty. Equality. Data. to brainstorm and collaborate with other app developers, designers, and our team.
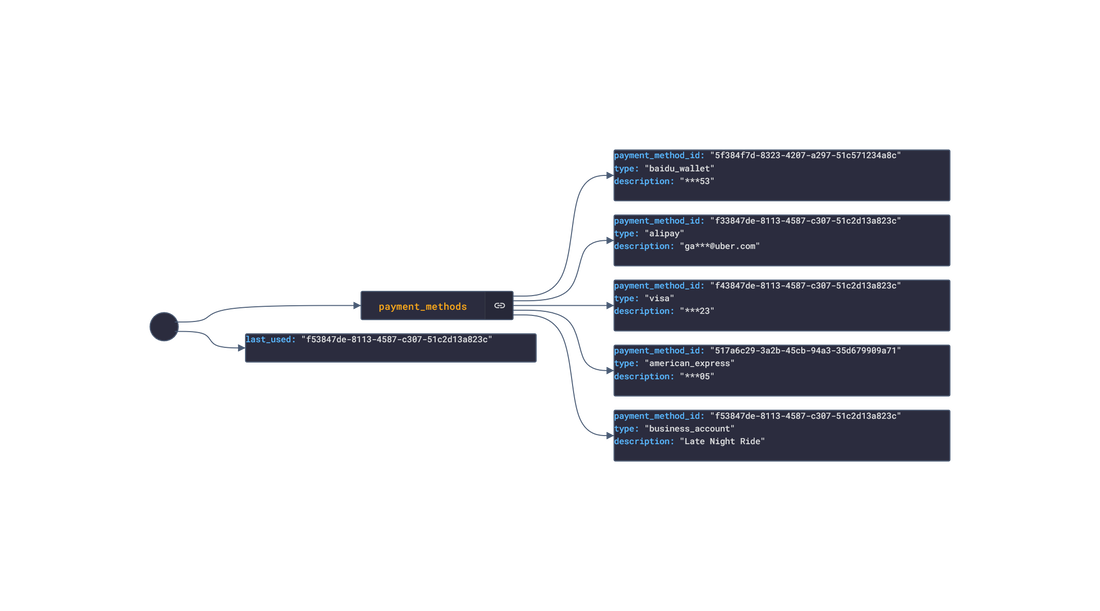
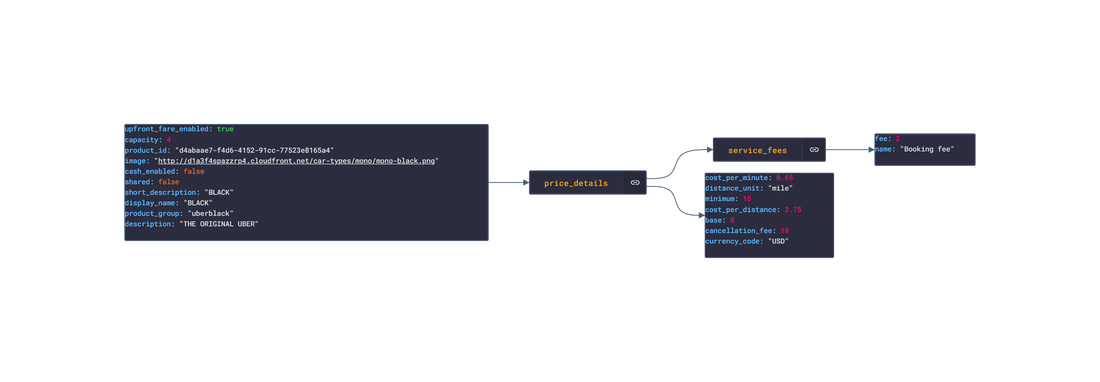
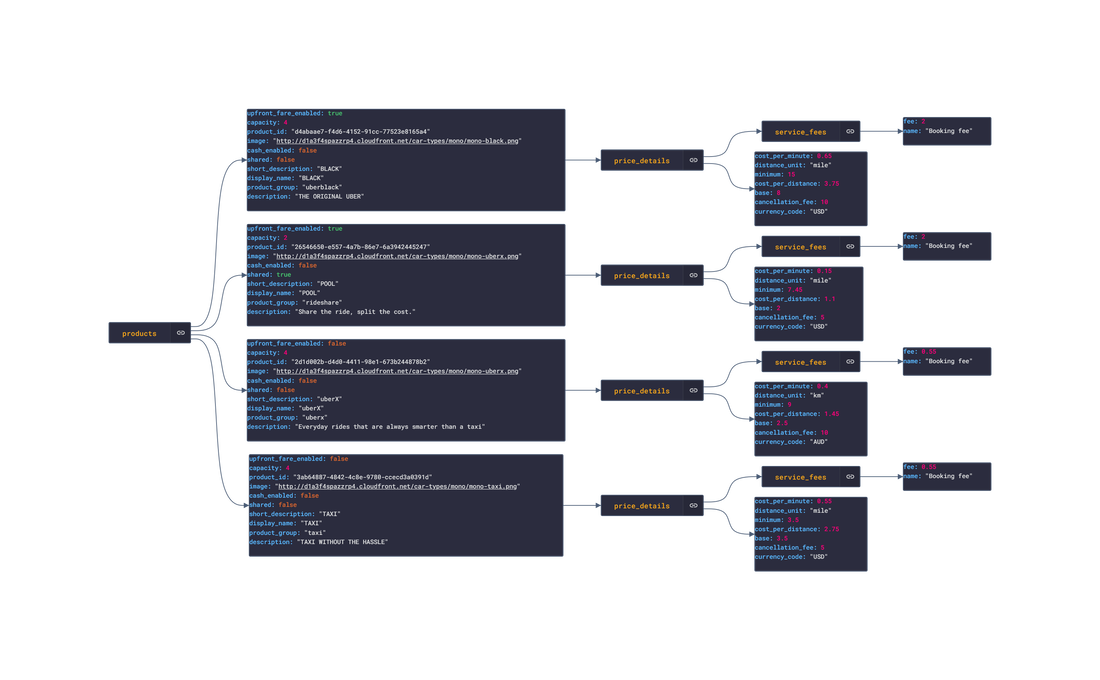
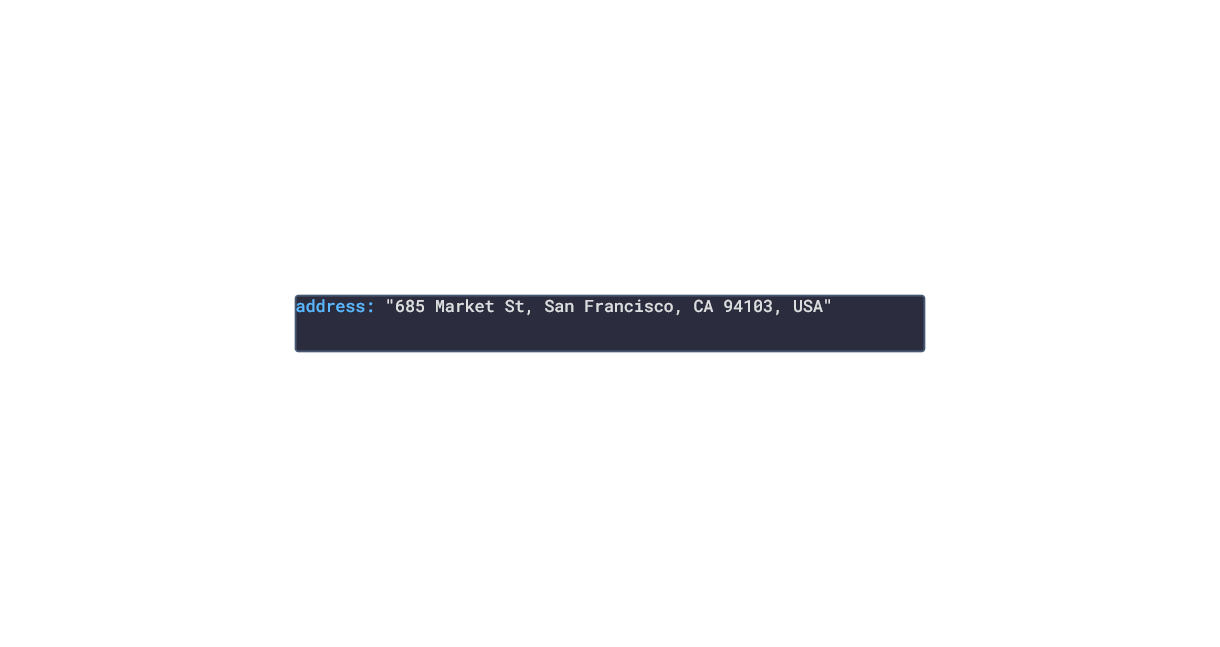
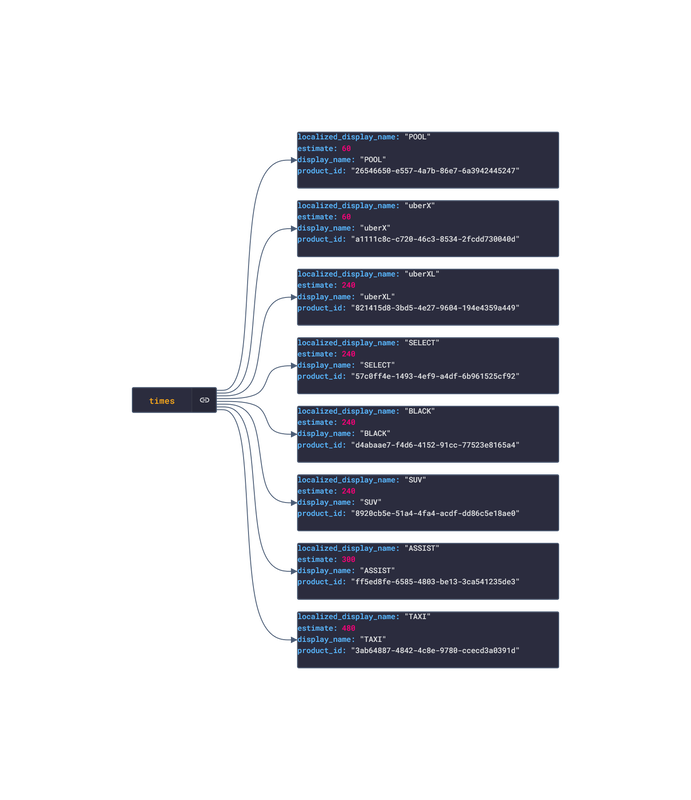
In this post, we are going deeper into the Dynamic Data project, looking at the Uber dynamic data (library available here on GitHub and at NPM). Opening the library, you’ll see there are ten types of data objects: ProductDetails, PriceEstimates, TimeEstimates, UserInfo, PaymentMethods, SavedPlaces, RideDetails, RideMapDetails, RideReceiptDetails and Products. Learn more about dynamic data generators and the benefits of artificial data in software development.  About the data source Uber (iOS|Android)is one of the largest ride-hailing apps available. Using the app, the user requests a ride along with the desired destination. The driver will travel towards the riders current location whilst they wait. Once the driver arrives, the rider confirms the drivers identity and travels with the driver towards the destination. After the trip, the rider can rate the trip with a 5-star system and tip the driver. There are several available rides depending on the number of guest riders and any mobility assistance needed. There are several other services offered by Uber:
Approach used Uber has an offical API that allows for the retrieval of ride and personal info. Using the API reference, several JSON objects were created and stored from the data types recorded. The index file of the package imports these data objects and exports them as a collection called “Data”. These mockup files make up the uber-data package Models Generated With JSON Crack The uber-mockup package imports the file above and goes through each attribute generating artificial (new) data using proprietary functions, such as those found in the utils package. For example, with the PriceEstimates object:
Use case ideas
Ideas to combine with some other data sources
Open-source data library We welcome contributions and forks to this data set, and look forward to seeing what developers build in our Liberty. Equality. Data. Slack channel. Considerations for next version/improvements
With Prifina developers can use the Dynamic Data Libraries natively in the App Studio to build direct to consumer apps where individuals can run them with their own user-held data. Join our Slack community; Liberty. Equality. Data. to brainstorm and collaborate with other app developers, designers, and our team.
|




























 RSS Feed
RSS Feed